
DDIA 第二章:定义非功能性要求
记录 DDIA 一书的阅读笔记
引言:功能性需求 vs. 非功能性需求
- 功能性需求 (Functional Requirements): 应用程序必须提供的功能(做什么)。例如,社交网络应用需要允许用户发帖、关注其他用户、查看时间线等。
- 非功能性需求 (Nonfunctional Requirements): 应用程序应该如何运作(怎么做)。例如,应用应该快速、可靠、安全、可扩展、易于维护等。
本章重点关注几个重要的非功能性需求:
- 性能 (Performance): 如何定义和衡量?
- 可靠性 (Reliability): 即使出现问题,也能继续正确工作。
- 可扩展性 (Scalability): 随着负载增长,有效地增加计算能力。
- 可维护性 (Maintainability): 长期易于维护。
案例学习:社交网络主页时间线
本章以一个简化的社交网络(类似 Twitter/X)为例,说明大规模系统中可能出现的问题。
需求
- 用户可以发布消息。
- 用户可以关注其他用户。
- 用户可以查看关注的人的最近帖子(首页时间线)。
假设
- 每天 5 亿条消息,平均每秒 5700 条。
- 高峰时每秒 15 万条消息。
- 平均每个用户关注 200 人,拥有 200 名粉丝(范围很广)。
关系型数据库方案
- 三个表:
users,posts,follows。 - 获取首页时间线的 SQL 查询:
SELECT posts.*, users.* FROM posts
JOIN follows ON posts.sender_id = follows.followee_id
JOIN users ON posts.sender_id = users.id
WHERE follows.follower_id = current_user
ORDER BY posts.timestamp DESC
LIMIT 1000
问题
- 性能瓶颈: 如果用户关注了很多人,查询会很慢。
- 扩展性挑战: 如果用户数和帖子数增长,查询会更慢。
改进方案:物化时间线
- 预计算每个用户的首页时间线,并存储在缓存中。
- 当用户发帖时,查找所有关注者,并将帖子插入到每个关注者的时间线中(扇出,fan-out)。
- 用户登录时,直接从缓存中提供时间线。
- 优点:加载时间线很快。
- 缺点:发帖时需要做更多工作(特别是名人发帖)。
- 优化:将名人的帖子单独处理。
描述性能 (Describing Performance)
主要性能指标
- 响应时间 (Response Time): 从用户发出请求到接收到响应的时间。
- 吞吐量 (Throughput): 系统每秒处理的请求数或数据量。
响应时间 vs. 吞吐量
- 通常存在联系。
- 负载增加时,响应时间会增长(由于排队)。
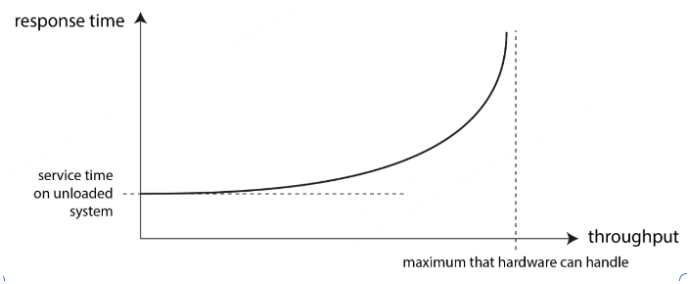
当服务吞吐量接近容量时,响应时间会由于排队而急剧增加
过载系统无法恢复 (When an overloaded system won’t recover)
- 重试风暴 (Retry Storm): 请求超时,客户端重试,导致负载进一步增加。
- 亚稳定故障 (Metastable Failure): 系统进入恶性循环,即使负载减少也无法恢复。
- 避免方法:
- 指数退避 (Exponential Backoff)
- 断路器 (Circuit Breaker)
- 令牌桶 (Token Bucket)
- 减载 (Load Shedding)
- 反压力 (Backpressure)
延迟与响应时间 (Latency and Response Time)
- 响应时间 (Response Time): 客户端看到的总时间。
- 服务时间 (Service Time): 服务实际处理请求的时间。
- 排队延迟 (Queueing Delay): 请求等待处理的时间。
- 网络延迟 (Network Latency/Network Delay): 请求和响应在网络中传输的时间。
- 延迟 (Latency): 请求未被积极处理的时间(潜伏期)。
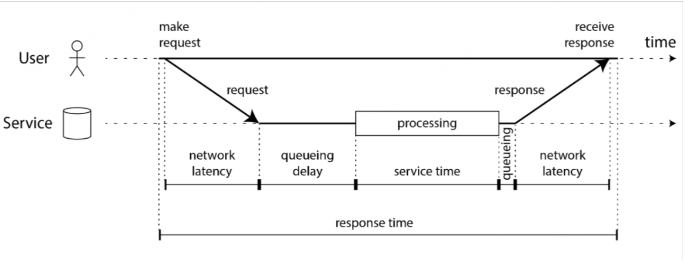
图2-4. 响应时间、服务时间、网络延迟和排队延迟
平均数、中位数与百分位点 (Averages, Medians, and Percentiles)
- 响应时间是分布,而不是单一数字。
- 平均值 (Average/Arithmetic Mean): 不适合描述“典型”响应时间。
- 中位数 (Median/50th Percentile/p50): 更好的指标,表示一半请求比它快,一半比它慢。
- 高百分位数 (95th, 99th, 99.9th Percentiles/p95, p99, p999): 尾部延迟,影响用户体验。
- [图 2-5] 展示了这些概念。
响应时间对用户的影响
- 快速服务通常更好,但难以量化影响。
- 一些研究表明,更快的响应时间可以提高点击率和转化率。
使用响应时间指标
- 尾延迟放大 (Tail Latency Amplification): 一个慢请求会拖慢整个用户请求(如果需要多个后端调用)。
- 服务级别目标 (SLO) 和服务级别协议 (SLA): 使用百分位数定义服务的预期性能。
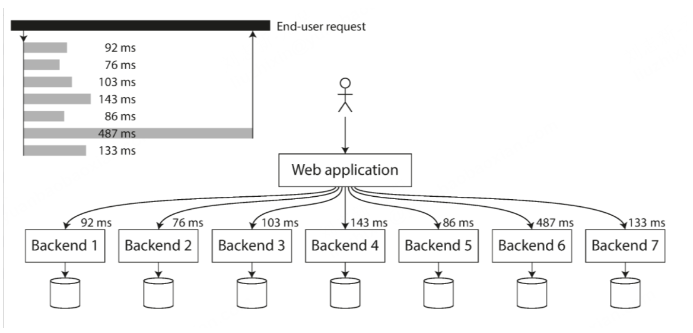
图 2-6. 当一个请求需要多次后端调用时,只需要一个缓慢的后端请求,就能拖慢整个终端用户的请求
计算百分位点
- 维护最近一段时间内请求响应时间的滚动窗口。
- 每分钟计算中位数和百分位数。
- 可以使用近似算法(HdrHistogram, t-digest, OpenHistogram, DDSketch)。
- 不能对百分位数进行平均,应该添加直方图。
可靠性与容错 (Reliability and Fault Tolerance)
可靠性定义
- 即使出现问题,也能继续正常工作。
- 期望:
- 应用程序表现出期望的功能。
- 允许用户犯错。
- 性能满足要求。
- 阻止未经授权的访问和滥用。
故障 vs. 失效
- 故障 (Fault): 系统的某个部分停止正常工作。
- 失效 (Failure): 系统整体停止提供所需服务。
- 故障不一定会导致失效。
容错 (Fault-Tolerant)
- 系统在某些故障发生时仍继续提供服务。
- 单点故障 (Single Point of Failure, SPOF): 某个部分的故障会导致整个系统失效。
- 容错性始终有限。
- 混沌工程 (Chaos Engineering): 故意诱发故障,测试容错机制。
硬件与软件缺陷
- 硬件故障:
- 磁盘故障(每年 2-5%)。
- SSD 故障(每年 0.5-1%)。
- CPU 核心错误。
- RAM 损坏。
- 数据中心故障。
- 软件缺陷:
- 系统性错误(跨节点相关)。
- 难以预料。
- 例子:闰秒 bug、失控进程、级联故障。
通过冗余容忍硬件缺陷
硬件冗余并不能完全保证不会失败,软件层面的容错更有效。
人类与可靠性
- 运维配置错误是导致服务中断的首要原因。
- 如何提高可靠性:
- 精心设计的抽象、API 和管理后台。
- 解耦易出错的地方和可能导致失效的地方。
- 提供沙箱环境。
- 彻底的测试。
- 快速回滚和恢复。
- 详细的监控(遥测)。
- 良好的管理实践和培训。
- 无责任事故报告 (Blameless Postmortems): 从事件中学习。
可靠性到底有多重要?
- 即使是“非关键”应用,也需要考虑可靠性。
- 数据丢失或损坏会造成严重后果。
- Post Office Horizon 丑闻:软件错误导致数百人被错误定罪。
可伸缩性 (Scalability)
定义
- 系统应对增加负载的能力。
- 不是一维标签,需要考虑具体问题。
描述负载
- 吞吐量: 每秒请求数、每天新增数据量、每小时购物车结账数等。
- 峰值: 同时在线用户数等。
- 其他统计特性: 读写比例、缓存命中率、每个用户的数据项数量等。
探讨负载增加的影响
- 增加负载,保持资源不变,性能如何变化?
- 增加负载,保持性能不变,需要增加多少资源?
- 线性可扩展性 (Linear Scalability): 加倍资源可以处理双倍负载。
共享内存、共享磁盘、无共享架构
共享内存****架构 (Shared-Memory Architecture):
多个 CPU 核心共享同一 RAM。在单台机器上,您可以通过使用多个进程或线程来实现并行性。属于同一进程的所有线程可以访问同一RAM。
垂直扩展(向上扩展):购买(或租用云实例)一个拥有更多CPU核心、更多RAM和更多磁盘空间的机器。
成本增长超过线性。一台规模加倍的机器往往处理的负载不到两倍。
共享磁盘架构 (Shared-Disk Architecture):
多个机器共享磁盘阵列(网络附加存储(NAS)或存储区域网络(SAN))。
可扩展性有限。争用和锁定开销限制了共享磁盘方法的可扩展性
无共享架构 (Shared-Nothing Architecture):
多个节点,每个节点拥有自己的 CPU、RAM 和磁盘。
水平扩展(向外扩展)。
潜力线性扩展。
需要显式的数据分区。
带来分布式系统复杂性。
可伸缩性原则
系统架构高度特定于应用。由于应用的需求可能会发展变化,通常不值得提前超过一个数量级来规划未来的扩展需求。
没有通用的可扩展架构。
在每个数量级负载增加时重新思考架构。
将系统分解成可以独立运行的小组件(微服务、分区、流处理、无共享架构)。
不要让事情变得比必要的更复杂。如果单机数据库可以完成工作,它可能比复杂的分布式设置更可取。自动扩展系统(根据需求自动增加或减少资源)很酷,但如果您的负载相当可预测,手动扩展的系统可能会有更少的运营惊喜。一个拥有五个服务的系统比拥有五十个服务的系统简单。
好的架构通常涉及到方法的实用混合。
可维护性 (Maintainability)
软件维护的挑战
- 需求变化。
- 环境变化。
- 修复错误。
- 遗留系统。
可维护性原则
- 可操作性 (Operability): 便于运维团队保持系统平稳运行。
- 监控。
- 自动化。
- 避免依赖单台机器。
- 良好的文档和操作模型。
- 良好的默认行为。
- 自我修复。
- 行为可预测。
- 简单性 (Simplicity): 让新工程师也能轻松理解系统。
- 使用众所周知、协调一致的模式和结构。
- 避免不必要的复杂性。
- 抽象。
- 可演化性 (Evolvability): 使工程师能够轻松地对系统进行改造。
- 与简单性和抽象性密切相关。
- 最小化不可逆性。
总结
本章介绍了几个重要的非功能性需求:性能、可靠性、可扩展性和可维护性。我们探讨了如何定义和衡量这些需求,并介绍了一些实现这些需求的一般原则。这些原则将在本书的后续章节中得到更详细的阐述。