
DDIA第九章: 分布式系统的麻烦
本章核心:深入探讨分布式系统中固有存在的各种问题和挑战,理解其复杂性和不可靠性来源,为后续章节讨论解决方案(如一致性与共识算法)打下基础。
核心观点: 分布式系统与单机系统有根本区别,最大的区别在于 部分失效(Partial Failure) 的可能性和 不确定性(Nondeterminism)。我们必须假设任何可能出错的地方 都 会出错(墨菲定律),并在此基础上设计容错系统。
1. 故障与部分失效 (Failure and Partial Failure)
- 单机系统:
- 行为相对可预测(确定性)。
- 故障通常是 完全失效(例如内核恐慌、蓝屏),而非介于工作和不工作之间。
- 设计目标是隐藏物理实现的模糊性,提供理想化的数学模型。
- 分布式系统:
- 必须面对现实世界的混乱。
- 部分失效: 系统的一部分可能以不可预知的方式发生故障,而其他部分继续运行。这是分布式系统的 决定性特征。
- 不确定性: 由于部分失效和网络延迟,操作的结果和时间变得不可预测。
- 处理方式差异:
- HPC (高性能计算): 倾向于将部分失效升级为完全失效(停止整个集群,从检查点恢复)。节点相对可靠,网络专用且可预测性较高。
- 云计算/互联网服务: 必须容忍部分失效。
- 高可用性要求: 服务通常需要 7x24 在线,不能轻易停止。
- 商用硬件: 成本低,但故障率相对较高。
- 规模效应: 节点越多,总有节点在发生故障。
- 运维优势: 允许滚动升级、动态替换故障节点。
- 地理分布: 网络延迟高且更不可靠。
- 容错是关键: 必须在软件层面构建容错机制,从不可靠的组件构建可靠的系统(类比:纠错码、TCP/IP)。
- 重要性: 即使是小型分布式系统,也需考虑部分失效,并进行充分测试(例如,混沌工程)。
2. 不可靠的网络 (Unreliable Networks)
- 基础: 无共享架构,节点通过网络通信。网络是唯一的通信途径。
- 网络类型: 异步分组网络(Asynchronous Packet Networks,如以太网、IP)。
- 核心问题: 消息发送不保证到达,也不保证何时到达。
- 请求-响应失败场景 (图 8-1):
- 请求丢失。
- 请求在队列中延迟。
- 远程节点失效。
- 远程节点暂时停止响应(如 GC 暂停)。
- 远程节点处理完,但响应丢失。
- 远程节点处理完,但响应延迟。
- 后果: 发送方无法区分上述情况,只知道 未收到响应。
- 常用处理:超时 (Timeout)
- 问题: 超时时长难以确定。
- 太长: 故障检测慢,影响用户体验或可用性。
- 太短: 容易误判(将暂时慢的节点当作故障),可能导致重复操作、级联故障。
- 理想 vs 现实: 现实网络没有最大延迟保证(无限延迟)。
- 延迟变化的原因 (排队):
- 网络交换机拥塞排队。在繁忙的网络链路上,数据包可能需要等待一段时间才能获得一个插槽(这称为网络拥塞)。如果传入的数据太多,交换机队列填满,数据包将被丢弃,因此需要重新发送数据包 - 即使网络运行良好。
- 目标机器操作系统接收队列(CPU 繁忙)则来自网络的传入请求将被操作系统排队,直到应用程序准备好处理它为止。
- 虚拟机监控器排队(CPU 切换)在虚拟化环境中,正在运行的操作系统经常暂停几十毫秒,因为另一个虚拟机正在使用 CPU 内核。。
- TCP 流量控制/拥塞避免(发送端排队)中节点会限制自己的发送速率以避免网络链路或接收节点过载【27】。这意味着甚至在数据进入网络之前,在发送者处就需要进行额外的排队。
- TCP 丢包重传引入延迟。
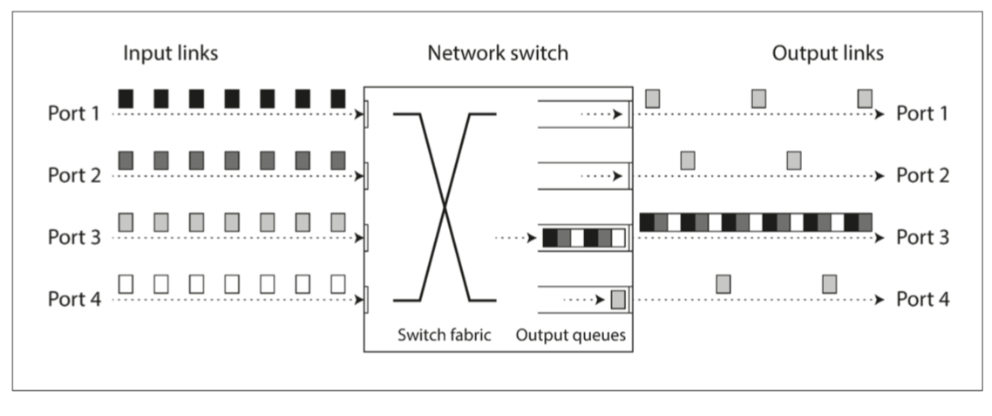 图 8-2 如果有多台机器将网络流量发送到同一目的地,则其交换机队列可能会被填满。在这里,端口 1,2 和 4 都试图发送数据包到端口 3
图 8-2 如果有多台机器将网络流量发送到同一目的地,则其交换机队列可能会被填满。在这里,端口 1,2 和 4 都试图发送数据包到端口 3
- 多租户环境加剧问题: 共享资源(网络、CPU)导致 “嘈杂邻居” 效应,延迟变化剧烈。
- 超时设置: 需要实验确定,或使用自适应超时(如 Phi Accrual 故障检测器)连续测量响应时间及其变化(抖动),并根据观察到的响应时间分布自动调整超时时间。TCP 的超时重传机制也是以类似的方式工作
- 问题: 超时时长难以确定。
UDP不可好传输-视频/语音: 应用程序必须使用静音填充丢失数据包的时隙(导致声音短暂中断),然后在数据流中继续。重试发生在人类层(“你能再说一遍吗?声音刚刚断了一会儿。”)
- 同步网络 vs 异步网络
- 同步网络 (如电路交换电话网): 预留固定带宽,无排队,延迟有界 (Bounded Delay)。当你通过电话网络拨打电话时,它会建立一个电路:在两个呼叫者之间的整个路线上为呼叫分配一个固定的,有保证的带宽量。这个电路会保持至通话结束【32】。例如,ISDN 网络以每秒 4000 帧的固定速率运行。呼叫建立时,每个帧内(每个方向)分配 16 位空间。因此,在通话期间,每一方都保证能够每 250 微秒发送一个精确的 16 位音频数据【33,34】。即使数据经过多个路由器,也不会受到排队的影响,因为呼叫的 16 位空间已经在网络的下一跳中保留了下来。而且由于没有排队,网络的最大端到端延迟是固定的。我们称之为 有限延迟(bounded delay)。
- 异步网络 (如 IP/以太网): 分组交换,动态共享带宽,有排队,延迟无界。
- 为何用异步? 优化 突发流量 (Bursty Traffic),提高网络利用率,成本更低。电路交换不适合网页、文件传输等。
- QoS/准入控制: 理论上可在分组网络模拟电路交换或提供统计上的有限延迟,但在通用数据中心/云中不常用。
- 关键 takeaway: 必须假设网络延迟是不可预测且可能无限的。软件必须能处理网络超时和故障。
3. 不可靠的时钟 (Unreliable Clocks)
- 时钟的重要性: 超时判断、性能监控、事件排序、调度、缓存过期、日志时间戳等。
- 分布式系统中的时间难题:
- 通信有时延且时延变化。
- 每个节点有独立的物理时钟(石英晶体),存在偏差 (drift)。
- 两种时钟:
- 日历时钟 (Time-of-day / Wall-clock time):
- 返回当前日期和时间(基于某个 epoch,如 Unix 时间戳)。(UTC 时间 1970 年 1 月 1 日午夜)以来的秒数(或毫秒)
- 通常使用 NTP (网络时间协议) 同步。
- 问题:
- 可能 向前或向后跳跃(NTP 大幅校正、闰秒)。
- 不适合测量 时间间隔 (duration)。
- 精度和同步准确性受 NTP 限制。
- 单调钟 (Monotonic clock):Linux 上的
clock_gettime(CLOCK_MONOTONIC),和 Java 中的System.nanoTime()- 保证 总是向前 移动。
- 适合测量 时间间隔(如超时、响应时间)。
- 绝对值无意义,不能跨节点比较。
- NTP 可以调整其速率 (skewing),但不能使其跳跃。
- 分辨率通常很高。
- 日历时钟 (Time-of-day / Wall-clock time):
- 时钟同步与准确性问题:
- 石英钟漂移 (drift): 受温度影响,即使同步也会累积误差 (e.g., 6ms per 30s, 17s per day @ 200ppm)。
- NTP 问题:
- 同步可能失败(时差过大、防火墙阻止)。
- 准确性受网络延迟限制(几十毫秒到秒级误差)。
- 服务器可能错误或配置不当(但客户端通常查询多个并忽略异常值)。
- 闰秒: 导致一分钟非 60 秒,破坏假设,曾引发系统故障(“smearing” 是一种缓解方式)。
- 虚拟机时钟: 虚拟化引入暂停,导致时钟看似跳跃。
- 用户设备时钟: 可能被用户故意设置错误。
- 依赖同步时钟的风险:
- 事件排序 (特别是 LWW - Last Write Wins):
- 极度危险!即使是很小的时钟误差 (<3ms 示例,图 8-3) 也可能导致因果关系颠倒,新数据被旧数据覆盖(数据丢失)。
- 无法区分顺序写入和并发写入。
- 相同时间戳需要 tiebreaker,仍可能违反因果。
- 结论: 不能依赖物理时钟进行跨节点事件排序。应使用 逻辑时钟 (Logical Clocks) (如 Lamport 时钟, 版本向量) 关注相对顺序。
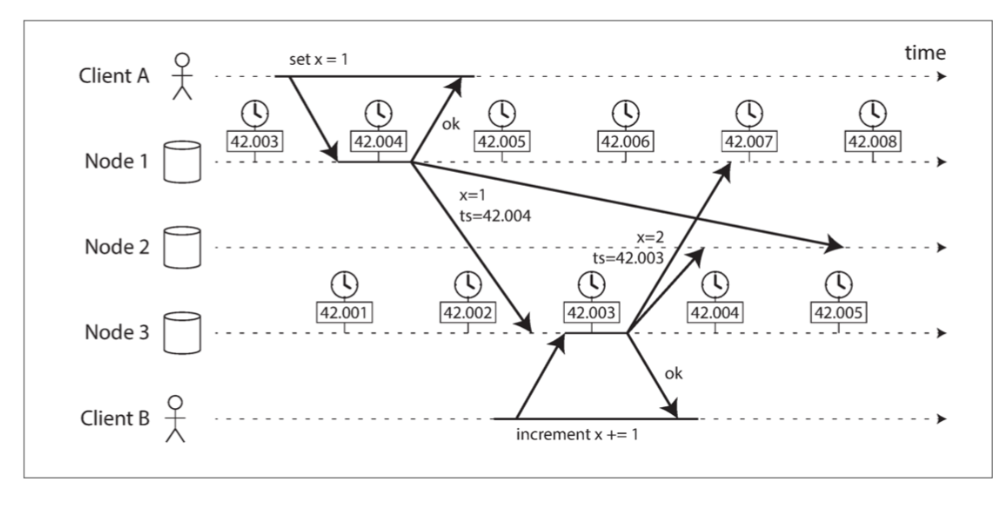 图 8-3 客户端 B 的写入比客户端 A 的写入要晚,但是 B 的写入具有较早的时间戳。
图 8-3 客户端 B 的写入比客户端 A 的写入要晚,但是 B 的写入具有较早的时间戳。- 客户端 A 在节点 1 上写入
x = 1;写入被复制到节点 3;客户端 B 在节点 3 上增加 x(我们现在有x = 2);最后这两个写入都被复制到节点 2. 写入x = 1的时间戳为 42.004 秒,但写入x = 2的时间戳为 42.003 秒,即使x = 2在稍后出现。当节点 2 接收到这两个事件时,会错误地推断出x = 1是最近的值,而丢弃写入x = 2。效果上表现为,客户端 B 的增量操作会丢失。
- 时钟读数是置信区间,而非精确时间点:将时钟读数视为一个时间点是没有意义的 —— 它更像是一段时间范围
- 读数精度 (微秒/纳秒) ≠ 实际准确度。
- 应视为
[最早可能时间, 最晚可能时间]的范围。 - 大多数系统不提供此不确定性信息。
- Google Spanner 的 TrueTime API: 是个例外,明确报告置信区间。
- 使用同步时钟实现全局快照 (如 Spanner):
- 用时间戳作事务 ID。当数据库分布在许多机器上,也许可能在多个数据中心中时,由于需要协调,(跨所有分区)全局单调递增的事务 ID 会很难生成。事务 ID 必须反映因果关系:如果事务 B 读取由事务 A 写入的值,则 B 必须具有比 A 更大的事务 ID,否则快照就无法保持一致。在有大量的小规模、高频率的事务情景下,在分布式系统中创建事务 ID 成为一个难以处理的瓶颈
- 挑战: 保证事务 ID 反映因果关系(B 读 A 写,则 B 的 ID > A 的 ID)。更晚的事务会有更大的时间戳
- Spanner 方案: 利用 TrueTime 的置信区间。如果区间 A 在区间 B 之前且不重叠,则 A 肯定发生在 B 之前。为保证这点,提交事务时会 等待 一个等于时钟不确定性的时间,确保因果一致性。需要高精度时钟源(GPS/原子钟)将不确定性降至毫秒级。
- 事件排序 (特别是 LWW - Last Write Wins):
- 关键 takeaway: 物理时钟不可靠且存在不确定性。避免基于物理时钟的跨节点排序。监控时钟偏差。
4. 进程暂停 (Process Pauses)
一个节点如何知道它仍然是领导者(它并没有被别人宣告为死亡),并且它可以安全地接受写入?
一种选择是领导者从其他节点获得一个 租约(lease),类似一个带超时的锁【63】。任一时刻只有一个节点可以持有租约 —— 因此,当一个节点获得一个租约时,它知道它在某段时间内自己是领导者,直到租约到期。为了保持领导地位,节点必须周期性地在租约过期前续期。
while (true) {
request = getIncomingRequest();
// 确保租约还剩下至少 10 秒
if (lease.expiryTimeMillis - System.currentTimeMillis() < 10000){
lease = lease.renew();
}
if (lease.isValid()) {
process(request);
}
}
线程在 lease.isValid() 行周围停止 15 秒,然后才继续, 它可能已经做了一些不安全的处理请求。
- 问题: 节点上的进程可能在任何时间点暂停相当长的时间(秒级甚至分钟级),然后恢复执行,但自身可能并未意识到暂停。
- 暂停原因:
- 垃圾回收 (GC): 特别是 “Stop-the-world” GC。
- 虚拟机: 挂起(suspend) 虚拟机(暂停执行所有进程并将内存内容保存到磁盘)并恢复(恢复内存内容并继续执行)、实时迁移、CPU 争用 (steal time)。暂停可以在进程执行的任何时候发生,并且可以持续任意长的时间
- 操作系统: 线程上下文切换、高负载下的调度延迟。
- I/O 操作: 同步磁盘访问(包括惰性类加载)、网络文件系统 (NFS)、块存储 (EBS)。即使代码没有包含文件访问,磁盘访问也可能出乎意料地发生 —— 例如,Java 类加载器在第一次使用时惰性加载类文件,这可能在程序执行过程中随时发生。
- 内存交换 (Swapping/Paging): 页面错误导致磁盘 I/O。
- 信号: 如
SIGSTOP(Ctrl-Z)。
分布式系统中的节点,必须假定其执行可能在任意时刻暂停相当长的时间,即使是在一个函数的中间。
- 后果:
- 节点对外表现为无响应,可能被误判为故障。
- 依赖时序的操作可能失败(如检查租约后,在执行操作前租约已过期)。
- 例子 (图 8-4 - 错误的锁实现): 客户端持有锁/租约 -> 发生长暂停 -> 租约过期,另一客户端获取锁并写入 -> 原客户端恢复,认为租约仍有效,继续写入 -> 数据损坏。
- 与实时系统的对比:
- 硬实时系统: 保证在截止时间 (deadline) 内响应,用于安全关键领域(航空、汽车)。需要特殊 OS (RTOS)、库、开发实践,成本高。
- 通用数据系统: 通常不是实时系统,必须容忍暂停。
- 缓解 GC 暂停影响:
- 将 GC 视为计划内中断,提前转移流量。
- 运行时通知应用即将 GC,应用停止接收新请求。
- 仅用 GC 处理短生命周期对象,定期重启进程处理长生命周期对象。
- 关键 takeaway: 必须假设进程可能随时长时间暂停。算法设计不能依赖短时间内的连续执行或精确计时。
5. 知识、真相与谎言 (Knowledge, Truth, and Lies)
核心问题: 在分布式系统中,节点无法获得关于系统状态的完全准确和及时的信息。其“知识”基于接收到的(或未收到的)消息,而这些消息可能延迟、丢失或过时。
真相由多数定义 (Quorums):
- 单个节点的判断不可靠(可能因网络隔离或暂停而产生错误认知)。
- 重要决策(如节点是否故障、谁是领导者)需要通过 法定人数 (Quorum) 的投票来决定(通常是 > N/2)。
- 系统只承认一个多数派的决定。
- 节点必须遵守法定人数的决定,即使与其本地视图矛盾(例如,被宣告死亡的节点必须下台)。
领导者和锁的问题:
- 节点自认为拥有领导权或锁,但可能已被多数节点认定为过时(因网络分区或暂停)。
- 如果过时的领导者/锁持有者继续操作,可能导致系统状态不一致或数据损坏 (Split Brain,图 8-4)。
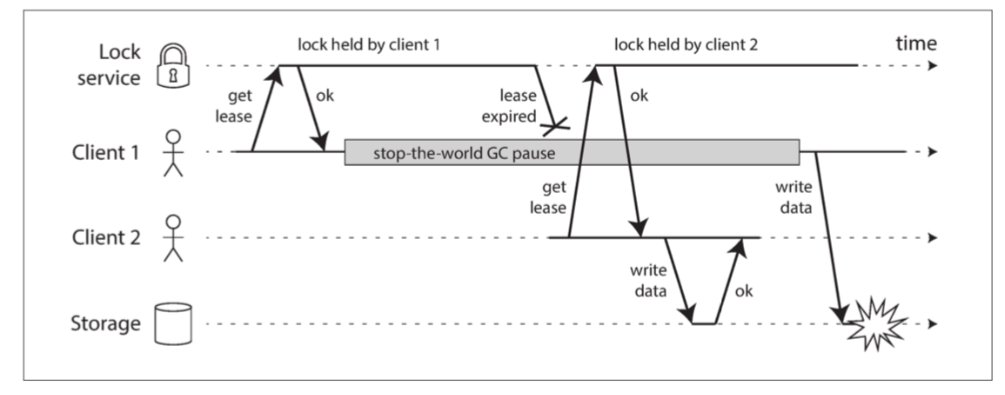 图 8-4 分布式锁的实现不正确:客户端 1 认为它仍然具有有效的租约,即使它已经过期,从而破坏了存储中的文件
图 8-4 分布式锁的实现不正确:客户端 1 认为它仍然具有有效的租约,即使它已经过期,从而破坏了存储中的文件
防护令牌 (Fencing Tokens) - 解决上述问题的机制:
- 原理:
- 每次授予锁/租约时,锁服务同时返回一个 单调递增 的数字(防护令牌)。
- 客户端每次对受保护资源进行写操作时,必须带上此令牌。
- 资源服务器记录处理过的最新令牌,并 拒绝 携带旧令牌的写请求。
- 效果 (图 8-5): 即使持有旧租约的客户端在暂停后恢复并尝试写入,其携带的旧令牌也会被资源服务器拒绝,从而阻止数据损坏。
- 要求: 资源服务器必须参与检查令牌。
- 实现: ZooKeeper 的
zxid或cversion可用作防护令牌。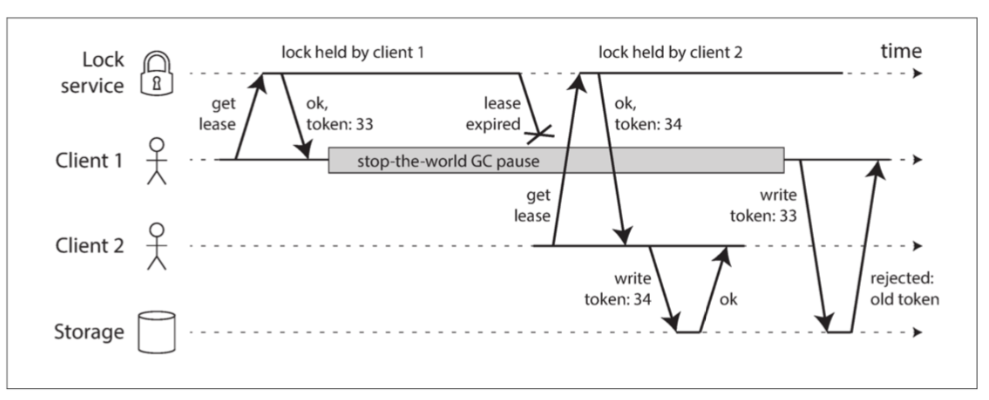 图 8-5 只允许以增加防护令牌的顺序进行写操作,从而保证存储安全
图 8-5 只允许以增加防护令牌的顺序进行写操作,从而保证存储安全
- 原理:
拜占庭故障 (Byzantine Faults):
- 定义: 节点可能 故意 撒谎、发送错误/恶意消息,或任意偏离协议。
- 拜占庭将军问题: 在存在叛徒(可能发送虚假消息)的情况下,忠诚的将军们如何达成一致行动计划。
- 适用场景:
- 高安全环境(航空航天 - 辐射导致错误)。
- 互不信任的环境(区块链、P2P 网络)。
- 在典型数据中心: 通常 假设不存在 拜占庭故障。节点被认为是不可靠但 诚实 (honest) 的(只会崩溃、延迟响应、状态过时,但不会撒谎)。
- 原因: 拜占庭容错协议非常复杂且成本高。内部系统节点通常受同一组织控制,可以信任。软件 Bug 通常影响所有节点,拜占庭容错帮助不大。安全依赖传统机制(认证、加密等)。
- “弱谎言”形式: 值得防御。
- 网络包损坏(TCP/UDP 校验和可能失效,应用层可加校验)。
- 软件 Bug、错误配置、无效输入(输入验证、合理性检查)。
- NTP 服务器错误(查询多个服务器,忽略异常值)。
6. 系统模型与现实 (System Models and Reality)
- 目的: 需要抽象模型来形式化描述系统的假设(网络、时钟、故障类型),以便设计和推理算法的正确性。
- 常用模型:
- 时序假设:
- 同步 (Synchronous): 网络延迟、暂停、时钟误差有 已知上界。(不现实)
- 部分同步 (Partially Synchronous): 大部分时间像同步系统,但偶尔会 超出边界。(较现实)
- 异步 (Asynchronous): 没有 任何时序假设,甚至没有时钟。(非常受限)
- 节点故障模型:
- 崩溃-停止 (Crash-stop): 节点崩溃后 永不恢复。
- 崩溃-恢复 (Crash-recovery): 节点崩溃后,能在 未来的某个时间恢复,通常假设持久化存储 (磁盘) 数据保留,内存状态丢失。
- 拜占庭 (Byzantine): 节点行为任意。
- 最常用模型: 部分同步 + 崩溃-恢复。
- 时序假设:
- 算法正确性:
- 通过 属性 (Properties) 定义。例如,防护令牌的唯一性、单调性、可用性。
- 如果算法在系统模型假设的所有可能情况下都满足其属性,则认为是正确的。
- 安全属性 (Safety) vs 活性属性 (Liveness):
- 安全属性: 保证 坏事永远不会发生 (Nothing bad ever happens)。
- 例子:唯一性、数据无损、无重复处理。
- 必须始终保持,即使在最坏情况下 (如所有节点崩溃)。
- 一旦违反,不可撤销。
- 活性属性: 保证 好事最终会发生 (Something good eventually happens)。
- 例子:可用性(请求最终收到响应)、最终一致性。
- 通常包含 “最终 (eventually)"。
- 可能在某些条件下才满足(如网络最终恢复、多数节点存活)。
- 安全属性: 保证 坏事永远不会发生 (Nothing bad ever happens)。
- 模型与现实的差距:
- 模型是 简化。现实世界可能发生模型未覆盖的故障(如磁盘损坏、固件 Bug)。
- 健壮的实现需要处理 “理论上不可能” 的情况(即使只是记录错误和退出)。
- 价值: 理论模型和分析有助于发现潜在问题,系统地解决复杂性,是设计可靠系统的第一步,与经验测试同等重要。
本章小结
- 分布式系统充满挑战,核心是 部分失效 和 不确定性。
- 网络不可靠(延迟、丢包)、时钟不可靠(偏差、跳跃)、进程会暂停。
- 故障 检测 本身就很难(超时机制不完美)。
- 构建容错系统需要在没有共享状态和全局视角的情况下,通过 消息传递 和 法定人数 (Quorum) 进行协调。
- 若非必要(为可伸缩性、容错性、低延迟),单机方案通常更简单。
- 系统模型(特别是部分同步+崩溃恢复)、安全性和活性属性是理解和设计分布式算法的重要工具。
- 本章聚焦于 问题,为下一章讨论 解决方案(一致性、共识)奠定基础。