
DDIA第八章: - 事务 (Transactions)
核心思想: 事务是一种机制,用于将多个读写操作组合成一个逻辑单元,以简化应用程序在面对并发和各种故障(硬件、软件、网络)时的编程模型。它提供安全保证,让应用可以忽略某些错误和并发问题。
目标:
- 可靠性 (Reliability): 处理各种潜在错误,防止数据损坏或不一致。
- 简化应用逻辑 (Simplified Programming Model): 将复杂的故障场景(如部分完成的操作)抽象为简单的提交 (Commit) 或 中止/回滚 (Abort/Rollback)。如果失败,应用可以安全地重试。
权衡: 事务并非免费,它有性能和可用性成本。有时放弃或弱化事务保证是合理的选择。理解事务提供的具体保证及其代价至关重要。
1. 事务的棘手概念 (The Slippery Concept of a Transaction)
- 历史: 概念源自 System R (1975),被广泛应用于关系数据库。
- NoSQL 趋势: 许多 NoSQL 数据库为了可伸缩性或可用性而放弃或弱化了传统事务。
- 误区: “事务与可伸缩性对立” 和 “事务是关键应用的绝对必需品” 都是夸张的说法。事实在于权衡。
2. ACID 的含义 (The Meaning of ACID)
ACID 是描述事务安全保证的缩写:原子性 (Atomicity), 一致性 (Consistency), 隔离性 (Isolation), 持久性 (Durability)。
- 重要警告: ACID 的实现并非完全标准化,不同数据库提供的保证可能不同。“ACID 兼容” 已成为一个模糊的营销术语。需要关注细节。
- BASE: “Basically Available, Soft State, Eventual consistency” - 定义更模糊,通常指“非 ACID”。
2.1. 原子性 (Atomicity)
- 含义: 指事务作为一个整体,要么全部成功 (Commit),要么全部失败 (Abort)。它不是关于并发(那是隔离性的范畴)。
- 关键: 发生错误时,事务能中止,并撤销/丢弃该事务已做的所有写入。提供 “宁为玉碎,不为瓦全 (all-or-nothing)” 的保证。
- 目的: 让应用从部分失败的担忧中解脱出来,可以安全地重试失败的事务。
- 别名: “可中止性 (Abortability)” 可能更准确。
2.2. 一致性 (Consistency)
- 多重含义警告: 这个词在数据库领域有多种含义 (副本一致性, CAP 一致性, 一致性哈希)。
- ACID 一致性含义: 指数据库需要始终满足应用定义的特定约束或不变量 (invariants) (例如,账户借贷平衡)。
- 关键: 一致性主要是应用程序的责任。数据库的原子性和隔离性可以帮助应用实现一致性,但数据库本身通常不强制应用级别的复杂不变量(除了简单的约束如外键、唯一性)。
- 结论: ‘C’ 在 ACID 中有点名不副实,它是应用属性而非数据库属性。
2.3. 隔离性 (Isolation)
- 含义: 并发执行 的事务相互隔离,不能相互干扰。
- 目标: 隐藏并发细节,让应用开发者感觉事务是串行执行的。
- 理论标准: 可串行化 (Serializability) - 保证并发事务的最终结果与它们按某种串行顺序执行的结果相同。
- 实践: 可串行化有性能成本,许多数据库默认使用更弱的隔离级别 (如读已提交、快照隔离),这些级别只能防止部分并发问题。
- 例子 (图 7-1): 两个事务并发递增计数器,若无隔离,可能导致更新丢失 (值只增 1 而不是 2)。
2.4. 持久性 (Durability)
- 含义: 一旦事务成功提交,其写入的数据不会丢失,即使发生硬件故障或数据库崩溃。
- 实现:
- 单节点: 通常意味着写入非易失性存储 (硬盘/SSD),通常配合预写日志 (WAL)。
- 复制系统: 可能意味着数据已成功复制到若干节点。
- 关键: 数据库必须等待写入/复制完成后才能报告提交成功。
- 重要警告 (没有完美的持久性):
- 磁盘/SSD 可能故障,固件可能有 Bug,
fsync可能不按预期工作。 - 断电可能导致 SSD 数据丢失 (尤其在高温下)。
- 存储栈的复杂交互可能导致崩溃后数据损坏。
- 数据可能发生未被检测到的“位衰减 (bit rot)”。
- 备份也可能损坏。
- 相关性故障可能摧毁所有副本。
- 异步复制可能在主库故障时丢失最近写入。
- 结论: 持久性是通过多种技术(磁盘写入、复制、备份)组合来降低风险,而非绝对保证。
- 磁盘/SSD 可能故障,固件可能有 Bug,
3. 单对象和多对象操作 (Single-Object and Multi-Object Operations)
- ACID 关注点: 原子性和隔离性主要针对多对象事务,即需要一次性更新多个记录/行/文档以保持数据同步的场景。
3.1. 多对象事务的需求
- 场景:
- 关系模型: 维护外键引用的有效性。
- 文档模型: 更新非规范化数据时,需要原子地修改多个文档(如图 7-2,邮件和未读计数)。
- 次级索引: 更新数据时,需要同步更新所有相关索引。
- 没有事务的后果: 若无原子性,错误处理复杂(图 7-3);若无隔离性,并发访问可能导致不一致(脏读,如图 7-2)。
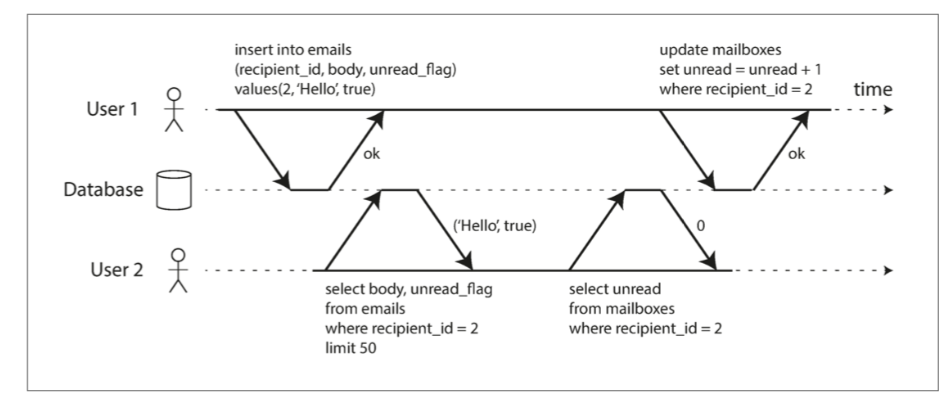 图 7-2 违反隔离性:一个事务读取另一个事务的未被执行的写入(“脏读”)。
图 7-2 违反隔离性:一个事务读取另一个事务的未被执行的写入(“脏读”)。
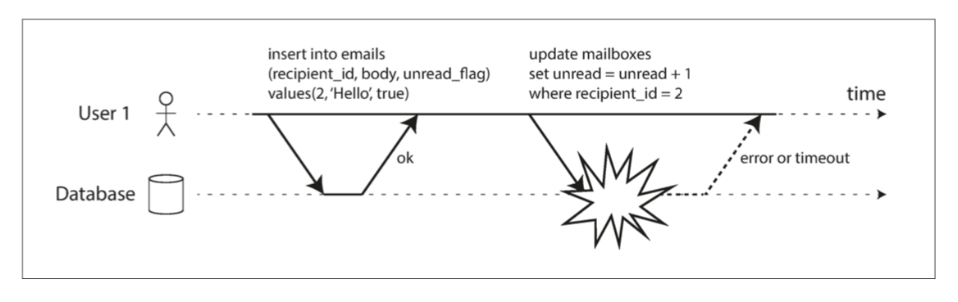 图 7-3 原子性确保发生错误时,事务先前的任何写入都会被撤消,以避免状态不一致
图 7-3 原子性确保发生错误时,事务先前的任何写入都会被撤消,以避免状态不一致
3.2. 单对象写入
- 原子性和隔离性仍然重要: 即使只修改单个对象(如写入大 JSON 文档),也需防止部分写入或并发读取部分更新的值。
- 实现: 通常通过崩溃恢复日志(原子性)和对象锁(隔离性)来保证。
- 原子操作: 许多数据库提供原子操作(如
increment,compare-and-set),可避免应用层读-改-写序列中的竞争条件。 - 注意: 单对象原子操作不是传统意义上的事务(涉及多对象多操作)。它们有时被称为“轻量级事务”或被错误地标记为“ACID”。
3.3. 处理错误和中止 (Handling Errors and Aborts)
- 核心优势: 事务失败时可以安全重试。数据库宁愿放弃事务也不留下部分完成的状态。
- 非 ACID 系统: 可能是“尽力而为”,错误恢复责任在应用。
- ORM 问题: 许多 ORM 框架在事务中止时不自动重试,将异常抛给上层,用户体验差。
- 重试的复杂性:
- 重复执行: 如果提交成功但确认消息丢失,重试会导致操作执行两次(需应用层幂等性)。
- 过载: 重试可能加剧过载(需限制次数、指数退避)。
- 永久错误: 对违反约束等永久错误重试无意义。
- 外部副作用: 事务中止无法撤销数据库外的副作用(如发邮件),可能需要两阶段提交 (2PC) 来协调。
- 客户端崩溃: 重试过程中客户端崩溃会丢失数据。
4. 弱隔离级别 (Weak Isolation Levels)
并发 BUG 难以发现和复现。数据库通过事务隔离来隐藏并发问题。可串行化是理论上的理想,但因性能问题,常用弱隔离级别。
警告: 弱隔离级别会导致各种并发异常 (竞争条件),造成数据损坏、财务损失等严重后果。即使是“ACID”数据库也可能默认使用弱隔离。
4.1. 读已提交 (Read Committed)
- 最基本的隔离级别。
- 保证:
- 没有脏读 (No Dirty Reads): 只能读取到已经提交的数据。事务写入只在提交后可见 (图 7-4)。防止看到部分更新或将被回滚的数据。
- 没有脏写 (No Dirty Writes): 只会覆盖已经提交的数据。如果两个事务想写同一个对象,后一个必须等前一个提交或中止。防止写入冲突导致数据混乱 (图 7-5)。
- 实现:
- 防止脏写: 通常使用行级写锁。事务修改对象前获取排它锁,持有至事务结束。
- 防止脏读 (常见方式): 使用 MVCC (多版本并发控制) 思想。对于每个被修改的对象,数据库保留旧的已提交版本和新的未提交版本。其他事务读取时,总是看到旧的已提交版本,直到写事务提交。这种方式避免了读操作需要加锁,提高了性能(“读不阻塞写”)。
- 局限: 不能防止读取偏差 (Read Skew) 或 丢失更新 (Lost Updates)。
- 流行度: Oracle, PostgreSQL, SQL Server 等数据库的默认级别。
4.2. 快照隔离和可重复读 (Snapshot Isolation and Repeatable Read)
动机: 解决读已提交无法处理的读取偏差/不可重复读 (Read Skew/Non-Repeatable Read) 问题。
- 例子 (图 7-6): Alice 在转账事务进行中查询两个账户余额,可能看到转账前一个账户和转账后另一个账户的状态,导致总额暂时看起来不正确。
- 问题场景: 数据库备份、长时间运行的分析查询、完整性检查。这些场景需要看到数据库在某个时间点的一致状态。备份可能会包含一些旧的部分和一些新的部分。如果从这样的备份中恢复,那么不一致(如消失的钱)就会变成永久的。
快照隔离 (Snapshot Isolation) 定义: 每个事务从数据库的一个一致性快照 (Consistent Snapshot) 中读取。事务启动时数据库中所有已提交的数据对该事务可见,即使这些数据后来被其他事务修改,该事务仍然看到启动时的旧版本数据。
关键原则: 读不阻塞写,写不阻塞读。 (与 2PL 不同)
实现 (MVCC):
- 是读已提交中防止脏读机制的通用化。数据库为对象保留多个已提交的版本。
- 每个事务分配一个单调递增的事务 ID (txid)。
- 写入数据时标记写入者的
txid。 - 行包含
created_by(创建者 txid) 和deleted_by(删除者 txid, 初始为空)。DELETE只是标记deleted_by,由后台垃圾回收清理(当所有活跃事务都不再需要访问旧版本数据时)。UPDATE=DELETE+INSERT(创建新版本)。 (如图 7-7) - 可见性规则: 事务读取时,根据其
txid和其他事务的状态决定哪些对象的版本可见:- 忽略启动时尚未提交或中止的事务所做的写入。
- 忽略已中止事务所做的写入。
- 忽略
txid比当前事务更大(即后启动)的事务所做的写入。 - 其他写入均可见。
- 总结: 对象版本可见,当且仅当:(1) 创建该版本的事务在读取事务开始时已提交;(2) 该对象未被标记为删除,或者标记删除它的事务在读取事务开始时尚未提交。
- 索引: 索引可以指向所有版本(查询时过滤),或使用仅追加/写时拷贝 (Append-Only/Copy-on-Write) B 树 (每次写入创建新树根,无需过滤,但需 GC)。
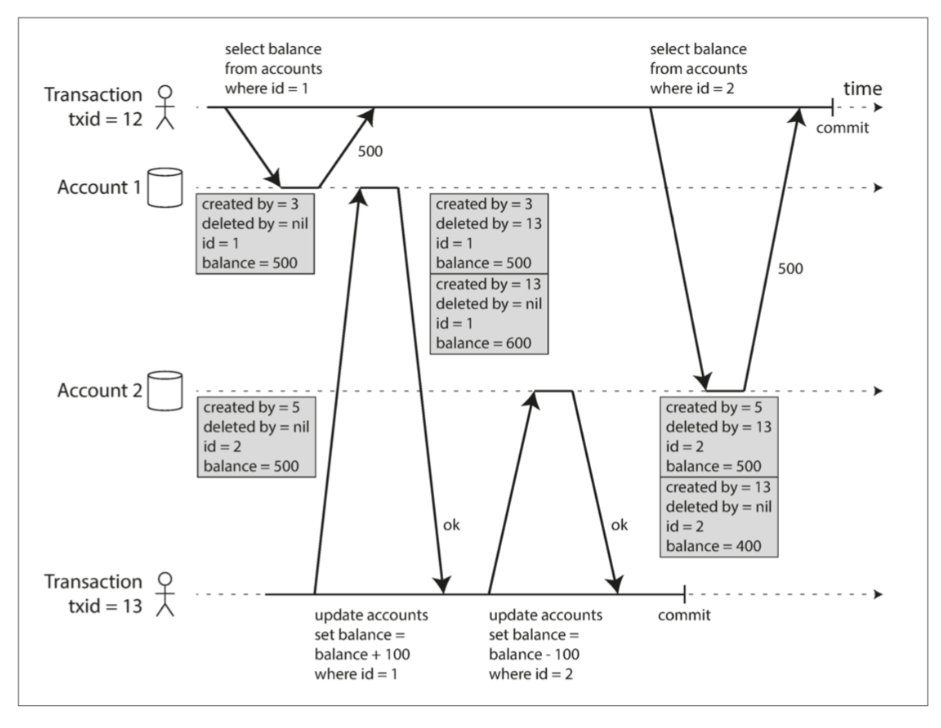 图 7-7 使用多版本对象实现快照隔离
图 7-7 使用多版本对象实现快照隔离
命名混淆:
- SQL 标准没有“快照隔离”,但定义了“可重复读”。
- PostgreSQL, MySQL/InnoDB 称其快照隔离级别为“可重复读”。
- Oracle 称其快照隔离级别为“可串行化”(实际并非真可串行化)。
- DB2 的“可重复读”实际上是可串行化。
- SQL 标准本身对隔离级别的定义有缺陷。
- 结论: “可重复读” 含义模糊不清。
4.3. 防止丢失更新 (Preventing Lost Updates)
- 问题: 两个事务并发执行读取-修改-写入 (Read-Modify-Write) 序列,后提交的事务覆盖了先提交事务的修改,导致第一个事务的更新丢失 (图 7-1)。
- 发生场景: 递增计数器、修改复杂值(如 JSON 列表)、并发编辑 wiki 页面。
- 解决方案:
- 原子写操作 (Atomic Write Operations):
- 数据库提供原子操作(如
UPDATE counters SET value = value + 1 WHERE ...,MongoDB $inc)。 - 这是最佳方案(如果适用)。通常通过对象上的排他锁或单线程执行实现。
- 风险: ORM 可能不使用原子操作,执行不安全的读-改-写。
- 数据库提供原子操作(如
- 显式锁定 (Explicit Locking):
- 应用程序使用
SELECT ... FOR UPDATE锁定要修改的行。 - 强制读-改-写序列串行化执行。
- 风险: 容易忘记加锁,引入 BUG。
- 应用程序使用
- 自动检测丢失更新 (Automatic Lost Update Detection):
- 允许多个读-改-写并行执行,数据库在提交时检测是否发生丢失更新。如果检测到,则中止冲突事务,强制其重试。
- 通常在快照隔离基础上实现。
- 优点: 自动进行,不易出错。
- 支持情况: PostgreSQL (Repeatable Read), Oracle (Serializable), SQL Server (Snapshot) 支持。MySQL/InnoDB (Repeatable Read) 不支持!
- 比较并设置 (Compare-and-Set, CAS):
- 原子操作,只有当值自上次读取后未改变时才允许更新。
UPDATE ... SET ... WHERE id = ? AND current_value = ?- 风险: 如果
WHERE子句从旧快照读取,可能不安全。需仔细检查数据库实现。
- 冲突解决和复制 (Conflict Resolution and Replication):
- 在多主/无主复制中,锁/CAS 不适用(因为可能没有单一最新副本)。
- 常用方法是允许并发写入,创建冲突版本 (Siblings),然后由应用代码或 CRDTs (如 Riak Data Types) 合并/解决冲突。
- 最后写入胜利 (LWW) 冲突解决方法极易丢失更新,需警惕。
- 原子写操作 (Atomic Write Operations):
4.4. 写入偏差与幻读 (Write Skew and Phantoms)
- 问题: 比脏写和丢失更新更微妙的并发冲突。当事务基于读取到的某些信息(前提)做出决定,然后写入数据库,但在写入时,这个前提可能已不再为真(因为其他事务并发修改了相关数据)。
- 例子 (图 7-8 医生值班): 两个医生同时检查,发现>1 人值班,于是都决定下班。两者都成功提交,导致无人值班,违反了“至少一人在班”的规则。
- 特征:
- 不是脏写或丢失更新(事务可能修改不同对象)。
- 只有并发时才出现。
- 可以看作丢失更新的泛化:两个事务读取相同对象集,然后基于读取结果更新部分(可能不同)对象。
- 防止写入偏差的挑战:
- 单对象原子操作无效。
- 快照隔离的自动丢失更新检测通常无效 (PostgreSQL, MySQL, Oracle, SQL Server 的 SI 实现都不能自动阻止写入偏差)。
- 需要真正的可串行化隔离才能自动防止。
- 数据库约束可能有用,但复杂的多对象约束支持有限。
- 显式锁定 (
SELECT FOR UPDATE) 可能有效,但前提是初始查询返回了需要锁定的行。
- 更多写入偏差例子:
- 会议室预订:并发预订同一房间同一时段。
- 多人游戏:两个玩家移动棋子到同一空格。
- 抢注用户名:并发注册相同用户名。
- 防止双重开支:并发消费导致余额为负。
- 幻读 (Phantoms):
- 定义: 一个事务的写入操作,改变了另一个并发事务中查询 (搜索条件) 的结果集。
- 与写入偏差的关系: 写入偏差通常涉及幻读。事务先执行一个查询(比如“检查房间 X 在时间 T 是否有预订”),发现没有匹配行(幻象),然后基于这个结果插入一条新记录。如果另一个事务同时执行相同逻辑,就会发生冲突。由于初始查询没有返回行,
SELECT FOR UPDATE无法锁定任何东西。 - 快照隔离避免了只读查询中的幻读,但在读写事务中,幻读会导致写入偏差。
- 物化冲突 (Materializing Conflicts):
- 一种手动解决幻读/写入偏差的方法。
- 人为地在数据库中创建锁对象行。例如,为每个会议室的每个时间段创建一行。事务预订时先锁定对应的时间段行,再检查冲突和插入。
- 将“幻象”变为对实际行的锁定冲突。
- 缺点: 复杂、易错、污染数据模型。应作为最后手段。
乐观锁在处理写入偏差问题中的适用性与局限性
写入偏差(Write Skew)是并发事务基于同一数据集的查询结果进行修改,导致整体数据不一致的问题。乐观锁在特定场景下可以缓解写入偏差,但并非完全可靠,尤其在强一致性需求中表现不足。
一、写入偏差的挑战与乐观锁的适用性
写入偏差的典型场景
用户提到的会议室预订、用户名抢注、防止双重开支等问题,本质都是多个事务基于同一初始状态执行逻辑,导致最终结果违反业务约束。例如:- 会议室预订:事务A和B同时查询到某时段未被预订,均尝试插入记录,导致重复预订。
- 用户名唯一性:两个事务同时检查用户名不存在后插入相同用户名,导致唯一性冲突。
乐观锁的适用条件
- 低冲突场景:乐观锁通过版本号(如
WHERE version = expected_version)检测冲突,适用于冲突概率低、重试成本可控的场景(如库存扣减)。 - 简单约束:若写入偏差的约束可通过单行版本号检测(如余额不能为负),乐观锁可能有效。例如,通过
UPDATE accounts SET balance = balance - 100 WHERE balance >= 100 AND version = ?防止透支。 - 局限性:若写入偏差涉及多对象关联(如医院值班需至少一名医生),乐观锁难以直接检测,需结合显式锁定或数据库约束。
- 低冲突场景:乐观锁通过版本号(如
乐观锁无法完全解决写入偏差的原因
- 快照隔离的局限性:在快照隔离级别下,事务可能基于过期快照数据决策,导致写入偏差无法被检测(如PostgreSQL、MySQL的默认隔离级别)。
- 无法覆盖复杂约束:乐观锁仅能验证单行版本号,无法处理跨行或多表关联的业务规则(如会议室时段冲突需检查时间段重叠)。
二、ABA问题的解决方案 ABA问题指数据值从A变为B后又恢复为A,导致乐观锁误判无冲突。以下是解决方法:
版本号扩展
- 数据库实现:在表中增加自增版本号字段(如
version),每次更新同时检查值和版本号。即使值恢复为A,版本号递增后必然不同,从而避免误判。 - 示例:若版本号已变化,更新失败。
UPDATE product SET stock = stock - 1, version = version + 1 WHERE id = 1 AND version = 1;
- 数据库实现:在表中增加自增版本号字段(如
时间戳替代
使用时间戳字段替代版本号,通过时间戳的严格递增性避免ABA问题。原子类型增强
在编程语言层面,使用AtomicStampedReference(Java)等支持值与版本号双重校验的原子类,避免内存操作中的ABA问题。
三、乐观锁无法处理强一致性需求的原因
最终一致性而非即时一致性
乐观锁依赖冲突检测和重试机制,事务提交时可能因版本冲突失败,需重试才能达成最终一致性。而强一致性要求操作即时生效(如金融交易扣款),无法容忍重试延迟。无法覆盖复杂事务
- 多对象原子性:乐观锁仅能保证单行原子操作,若事务涉及多行更新(如转账需同时修改两个账户),需依赖数据库事务或分布式锁,乐观锁无法独立实现。
- 实时性要求:在高并发写场景(如秒杀),乐观锁的重试开销可能导致性能骤降,而悲观锁通过预加锁可避免瞬时冲突。
依赖业务逻辑
乐观锁需业务层处理冲突(如重试、回滚),而强一致性通常需数据库或系统底层保障(如串行化隔离、分布式一致性协议)。
总结与建议
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 低冲突写入偏差 | 乐观锁 + 版本号/时间戳 | 适用于简单约束(如库存扣减),冲突概率低时性能高 |
| 高冲突或复杂约束 | 悲观锁(SELECT FOR UPDATE)或串行化隔离 | 避免重试开销,确保强一致性 |
| ABA问题 | 版本号扩展或 AtomicStampedReference | 防止值恢复导致的误判 |
| 多对象强一致性 | 数据库事务(如MySQL串行化隔离)或分布式锁 | 覆盖跨行/跨表操作,确保原子性 |
关键结论:
- 乐观锁适用于低冲突、简单业务规则的场景,需配合版本号解决ABA问题。
- 强一致性需求需依赖悲观锁、串行化隔离或分布式一致性协议(如Raft、Paxos)。
5. 可串行化 (Serializability)
- 最强的隔离级别。
- 保证: 数据库保证并发事务的执行结果,等同于它们按照某个串行顺序一个接一个执行的结果。
- 优点: 防止所有前面讨论的竞争条件 (脏读、脏写、读偏、丢失更新、写偏、幻读)。如果事务单独运行时正确,并发运行时也保证正确。
- 挑战: 实现可串行化的传统方法有性能代价。
5.1. 真的串行执行 (Actual Serial Execution)
- 概念: 完全禁止并发,在单个线程上一次只执行一个事务。
- 可行性基础:
- RAM 成本下降,活跃数据集可放入内存,执行快。
- OLTP 事务通常很短,读写量少。
- 实现: VoltDB/H-Store, Redis, Datomic。
- 要求 & 实现方式:
- 存储过程: 为避免交互式事务的网络延迟,应用需将整个事务逻辑封装在存储过程中提交给数据库 (图 7-9)。
- 优点: 避免锁开销,简单。
- 缺点 (存储过程): 特定语言 (PL/SQL, T-SQL 等) 可能老旧难用;代码难管理、调试、部署、监控;对数据库性能敏感。 (现代实现使用通用语言如 Java, Lua)
- 确定性: 若用于复制 (如 VoltDB),存储过程必须是确定性的。
- 性能限制: 吞吐量受限于单个 CPU 核。
- 伸缩性 (分区):
- 将数据分区,每个分区运行独立的串行处理线程。
- 单分区事务: 性能可随 CPU 核数线性扩展。
- 跨分区事务: 需要协调,性能显著降低,伸缩性有限。
- 总结 (适用条件):
- 事务必须小而快。
- 活跃数据集需能放入内存。
- 写入吞吐量能在单核处理,或大部分事务是单分区的。
5.2. 两阶段锁定 (Two-Phase Locking, 2PL)
- 传统标准算法 实现可串行化 (用了几十年)。
- 注意: 2PL != 2PC (两阶段提交)。
- 工作方式: 比读已提交的锁更严格。
- 读锁 (共享锁): 事务读对象前获取共享锁。多个事务可同时持有共享锁。阻塞想获取排它锁的写事务。
- 写锁 (排它锁): 事务写对象前获取排它锁。一次只有一个事务能持有。阻塞其他所有读或写事务。
- 锁升级: 读后写可能需要将共享锁升级为排它锁。
- 两阶段:
- 阶段一 (增长阶段): 事务执行,获取锁。
- 阶段二 (缩减阶段): 事务结束时 (提交或中止),释放所有持有的锁。 (不能在事务中间释放锁)
- 实现: MySQL (InnoDB), SQL Server 的 Serializable 级别;DB2 的 Repeatable Read 级别。
- 性能问题:
- 锁开销: 获取和释放锁本身有成本。
- 并发性降低: 读写互相阻塞,事务等待时间长且不可预测。一个慢事务可能拖慢整个系统。
- 死锁 (Deadlock): 事务互相等待对方释放锁。数据库需自动检测死锁,并中止其中一个事务让其重试,导致浪费工作。在 2PL 中比在读已提交中更常见。
- 防止幻读:
- 谓词锁 (Predicate Locks): 理论上的解决方案。锁住满足某个搜索条件的所有对象(包括当前不存在但可能被插入的对象)。例如,锁住
room_id = 123 AND time BETWEEN 12:00 AND 13:00。性能差,实现复杂。 - 索引范围锁 (Index-Range Locking / Next-Key Locking): 谓词锁的实用近似。将锁附加到与查询条件相关的索引条目或范围上。例如,锁住
room_id = 123的索引项,或time索引中 12:00-13:00 的范围。能有效防止幻读和写入偏差,开销较低。是 2PL 数据库常用方法。无合适索引时可能退化为表锁。
- 谓词锁 (Predicate Locks): 理论上的解决方案。锁住满足某个搜索条件的所有对象(包括当前不存在但可能被插入的对象)。例如,锁住
5.3. 可串行化快照隔离 (Serializable Snapshot Isolation, SSI)
- 较新的算法 (2008),提供完全可串行化,性能接近快照隔离。
- 实现: PostgreSQL (>= 9.1) 的 Serializable 级别, FoundationDB。
- 核心思想:
- 乐观 (Optimistic) 并发控制 (与 2PL 的悲观相对)。
- 事务在快照隔离基础上执行,不阻塞读写。
- 提交时检测: 数据库检查是否存在串行化冲突 (即执行是否等价于某个串行顺序)。
- 如果检测到冲突,中止事务,强制其重试。
- 乐观控制的权衡:
- 优点: 在低争用、有足够容量时性能优于悲观锁。
- 缺点: 在高争用或接近满载时,大量中止和重试会降低性能。
- SSI 检测机制 (基于检测"过时前提"):
- 检测对旧 MVCC 对象版本的读取 (Detecting Reads of Stale MVCC Versions):
- 事务 T1 读取数据时,忽略了另一个未提交事务 T2 的写入 (根据 MVCC 规则)。
- 如果 T2 在 T1 提交之前提交了,那么 T1 的读取就是基于一个过时 (stale) 的快照。
- 检查: T1 提交时,检查是否有任何它在读取时忽略的写入现在已经被提交。如果有,T1 必须中止。 (如图 7-10)
- 检测影响先前读取的写入 (Detecting Writes That Affect Prior Reads):
- 事务 T1 读取了某些数据。
- 之后,在 T1 提交之前,另一个事务 T2 写入 (修改/删除/插入) 了影响 T1 读取结果的数据 (幻读场景)。
- 实现: 数据库跟踪事务读取了哪些索引范围。当事务写入时,检查是否有其他正在进行中的事务最近读取了将被修改的索引范围。
- 通知: 如果发现冲突,写入事务会“通知”读取事务,其读取可能已过时。
- 中止逻辑: 当事务要提交时,检查是否收到过这种“过时”通知,且导致过时的那个写事务已经提交。如果是,则当前事务必须中止。 (如图 7-11)
- 检测对旧 MVCC 对象版本的读取 (Detecting Reads of Stale MVCC Versions):
- 性能:
- 优点: 读不阻塞写,写不阻塞读,查询延迟更可预测。特别适合读密集型工作负载 (只读查询无需锁)。可扩展到多核/多节点 (FoundationDB)。
- 依赖中止率: 整体性能取决于有多少事务被中止。长时间运行的读写事务更容易冲突和中止。对慢事务可能比 2PL 更敏感。
本章小结
- 事务是处理并发和故障的关键抽象,简化了应用开发。
- 核心目的是提供原子性(全或无)、隔离性(隐藏并发)、持久性(数据不丢)以及帮助应用实现一致性。
- 并发控制是核心挑战,弱隔离级别(读已提交、快照隔离/可重复读)性能好但会引入各种竞争条件(脏读、脏写、读偏、丢失更新、写偏、幻读)。开发者需理解并处理这些问题。
- 可串行化是最高隔离级别,防止所有竞争条件,但实现有挑战。
- 实现可串行化的方法:
- 真的串行执行: 简单,但在特定约束下(内存、单核吞吐量、短事务)才可行。
- 两阶段锁定 (2PL): 传统方法,通过锁实现,但性能和死锁是问题。
- 可串行化快照隔离 (SSI): 新方法,乐观机制,性能接近快照隔离,是未来趋势。
- 事务概念适用于各种数据模型,本章主要在单节点背景下讨论,分布式事务的挑战将在后续章节探讨。