
DDIA第七章: - 分区 (Partitioning)
核心思想: 当数据量或吞吐量增长到单机无法处理时,需要将数据分散到多个节点上。这种将大型数据库分解为多个小型、独立部分的过程称为 分区 (Partitioning) 或 分片 (Sharding)。
目标:
- 可伸缩性 (Scalability): 分摊存储压力和查询负载到多个节点、磁盘和 CPU 上。
- 高吞吐量: 允许并行处理查询,增加整体读写能力。
- 高可用性 (配合复制): 通常与复制结合,每个分区有多个副本分布在不同节点上,提高容错性。
术语澄清:
- 分区 (Partition): 通用术语。
- 分片 (Shard): MongoDB, Elasticsearch, SolrCloud.
- 区域 (Region): HBase.
- 表块 (Tablet): Bigtable.
- 虚节点 (vnode): Cassandra, Riak.
- 虚桶 (vBucket): Couchbase.
- 网络分区 (Network Partition): 与数据分区无关,指网络故障 (第八章讨论)。
1. 分区与复制 (Partitioning and Replication)
- 分区和复制通常 结合使用。
- 数据先分区,然后每个分区的副本存储在多个节点上。
- 一个节点可以同时是某些分区的 领导者 (Leader/Primary) 和其他分区的 追随者 (Follower/Secondary) (如图 6-1)。
- 分区方案的选择与复制方案的选择通常是 独立 的。本章主要关注分区,暂时忽略复制细节。
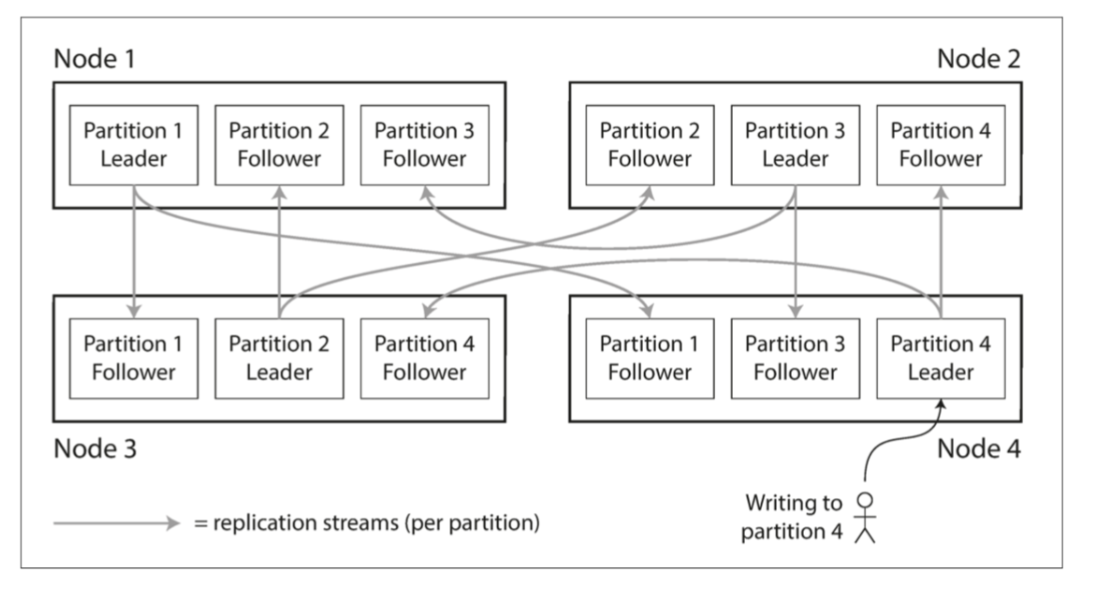 图 6-1 组合使用复制和分区:每个节点充当某些分区的主库,其他分区充当从库。
图 6-1 组合使用复制和分区:每个节点充当某些分区的主库,其他分区充当从库。
2. 键值数据的分区 (Partitioning of Key-Value Data)
目标: 将数据和查询负载 均匀分布,避免 偏斜 (Skew) 和 热点 (Hot Spots)。
方法:
2.1. 根据键的范围分区 (Partitioning by Key Range)
- 概念: 为每个分区分配一段 连续的键范围 (类似百科全书按卷划分)。
- 优点:
- 范围查询高效: 相邻的键存储在一起,便于扫描 (例如按时间戳查询某个月的数据)。
- 缺点:
- 易产生热点: 特定的访问模式可能导致所有请求集中到少数分区 (例如,主键为时间戳时,当前时间的写入都集中在最后一个分区)。
- 边界调整: 分区边界需要根据数据动态调整或手动设置,以求均匀分布。
- 缓解热点: 可以在主键前加上非连续性的前缀 (如传感器 ID + 时间戳),但这会使跨前缀的范围查询变复杂。
- 实例: Bigtable, HBase, RethinkDB, MongoDB (< 2.4)。
示例:
假设一个物联网系统,存储 传感器数据,主键原本设计为 时间戳(如
20230915-1200),所有传感器数据按时间顺序写入。此时,主键是连续的,会导致以下问题:
- 写入热点:最新时间戳的数据总是写入最后一个分区。
- 存储倾斜:最后一个分区的负载远高于其他分区。
解决方案:添加非连续性前缀
将主键改为 传感器 ID + 时间戳,例如: sensor1_20230915-1200、sensor2_20230915-1200、sensor3_20230915-1200。 此时,主键的前缀(传感器 ID)是 非连续的,数据分布会发生以下变化:
1. 数据写入分散到不同分区
假设按主键的字母顺序分区,可能的键范围分配如下:
- 分区1:
sensor1_000000~sensor1_999999 - 分区2:
sensor2_000000~sensor2_999999 - 分区3:
sensor3_000000~sensor3_999999
不同传感器的数据被隔离到独立的分区中,写入负载被分散,避免了热点。
2. 牺牲范围查询效率
如果查询 所有传感器在某个时间段的数据(例如 20230915 全天的数据),需要:
- 遍历所有传感器的前缀(sensor1、sensor2、sensor3)。
- 对每个传感器分别查询时间范围
sensorX_20230915-*。 - 合并所有结果。
这比直接按连续时间戳查询复杂得多。
2.2. 根据键的散列分区 (Partitioning by Hash of Key)
- 概念: 对每个键应用 散列函数 (Hash Function),根据散列值将键分配到对应范围的分区。
- 散列函数要求: 分布均匀即可,无需加密强度。注意某些语言内置哈希函数可能不适用于分布式系统 (如 Java
Object.hashCode(),同一个键可能在不同的进程中有不同的哈希值)。 - 优点:
- 负载分布更均匀: 能有效打散偏斜的键,减少热点风险。
- 缺点:
- 范围查询低效: 相邻键的散列值可能差异很大,导致它们分散在不同分区,破坏了排序性。范围查询通常需要 分散/聚集 (Scatter/Gather) 到所有分区。
- 一致性哈希 (Consistent Hashing):
- 特指 Karger 等人提出的使用随机分区边界的方法,主要用于 CDN 缓存。
- 在数据库领域常被误用,其实质多为 散列分区 (Hash Partitioning)。其原始定义中的再平衡方式对数据库并不理想。最好避免使用此术语,除非特指原始算法。
- 混合策略 (Cassandra):
- 使用 复合主键 (Compound Primary Key)。
- 只对主键的 第一部分 进行散列分区。
- 主键的 其余部分 用于在分区 内部进行排序 (类似 SSTable 中的聚集索引)。
- 允许在 给定第一部分键值 的情况下,对后续部分进行高效的范围扫描。适用于一对多关系 (如
(user_id, update_timestamp))。
- 实例: Cassandra, MongoDB (≥ 2.4),如果你使用了基于散列的分区模式,则任何范围查询都必须发送到所有分区 Voldemort, Riak, Couchbase。
2.3. 负载偏斜与热点消除 (Skewed Workloads and Relieving Hot Spots)
- 问题: 即使使用散列分区,如果大量读写集中在 同一个键 上 (如名人账户更新),仍然会产生热点。
- 解决方案 (应用层):
- 对于极少数热点键,在键名 开头或结尾添加随机数或哈希值 (如
celebrity_id_1,celebrity_id_2…),将写请求分散到不同分区。 - 缺点: 读取时需要查询所有加了后缀的键并合并结果,增加了读取复杂度。需要机制来追踪哪些键是热点。
- 对于极少数热点键,在键名 开头或结尾添加随机数或哈希值 (如
- 未来: 数据系统可能会自动检测和处理这种偏斜。
3. 分区与次级索引 (Partitioning and Secondary Indexes)
- 挑战: 次级索引 (用于按值查找,而非主键) 如何与数据分区协同工作?
- 两种主要策略:
3.1. 基于文档的次级索引分区 (Document-Partitioned Indexes / Local Indexes)
- 概念: 每个分区 独立维护 自己所存储文档的次级索引。索引只覆盖该分区内的数据。
- 写入: 简单。只需更新包含该文档 ID 的分区的本地索引。
- 读取: 复杂且可能低效。需要 分散/聚集 (Scatter/Gather) 查询到 所有分区,然后合并结果。容易放大尾部延迟。
- 实例: MongoDB, Riak, Cassandra, Elasticsearch, SolrCloud, VoltDB。
3.2. 基于关键词的次级索引分区 (Term-Partitioned Indexes / Global Indexes)
- 概念: 构建一个 全局索引,覆盖所有分区的数据。然后,索引本身也进行分区 (按索引的关键词或其哈希值分区,而非按文档 ID)。
- 例如,所有
color:red的索引条目可能存储在一个特定的索引分区,而color:blue的条目在另一个索引分区。这些条目指向位于任何数据分区的文档。
- 例如,所有
- 读取: 高效。客户端只需向 包含该关键词的那个索引分区 发送查询请求即可,无需 Scatter/Gather。
- 写入: 复杂且较慢。写入单个文档可能需要更新 多个不同节点上的索引分区 (因为文档包含的多个关键词可能落在不同索引分区)。
- 理想情况下需要跨分区的分布式事务,但很多系统不支持。
- 实践中,全局索引更新通常是 异步 (Asynchronous) 的,存在短暂的读写不一致窗口。
- 实例: Riak Search, Oracle DW (可选), DynamoDB 全局次级索引 (更新通常 < 1s)。
4. 分区再平衡 (Rebalancing Partitions)
原因: 集群状态变化 (增/减节点、节点故障、数据/负载增长)。
目标:
- 再平衡后,负载 (存储、读写) 在节点间 公平共享。
- 再平衡期间,数据库 持续可用 (能处理读写请求)。
- 最小化数据移动量,加快再平衡速度,减少网络和 I/O 负担。
策略:
4.1. 反面教材:Hash Mod N
- 方法:
partition = hash(key) mod N(N 是节点数)。 - 问题: 当 N 改变时,几乎所有 的键都需要重新映射到不同的节点,导致大规模数据迁移,成本极高。应避免使用。
4.2. 固定数量的分区 (Fixed Number of Partitions)
- 概念:
- 在集群创建初期就设定一个 远超节点数量 的 固定分区总数 (例如 10 个节点,1000 个分区)。
- 将这些分区大致均匀地 分配给现有节点 (每个节点管理多个分区)。
- 再平衡 (添加节点): 新节点从现有节点 “窃取” 部分分区,直到分区再次均匀分布。
- 再平衡 (移除节点): 故障/移除节点的分区被 重新分配 给其他剩余节点。
- 优点:
- 键到分区的映射 保持不变,只需移动整个分区。
- 操作相对简单。
- 缺点:
- 初始分区数选择困难: 需要预估未来最大节点数。设置太少限制扩展,设置太多增加管理开销。
- 分区大小随数据总量增长: 如果数据量变化巨大,分区可能变得过大 (迁移/恢复慢) 或过小 (效率低)。
- 实例: Riak, Elasticsearch, Couchbase, Voldemort。
分区迁移实现
在固定数量分区的架构中,分区迁移需要在不中断服务的情况下实现数据的平滑转移,同时保证数据一致性。以下是其核心实现机制:
1. 元数据管理
- 分区映射表:系统维护一个全局元数据(如通过 ZooKeeper、etcd 等协调服务),记录每个分区当前所属的节点。
- 版本控制:元数据包含版本号,每次分区迁移时版本号递增,客户端和节点通过版本号感知变更。
2. 迁移流程
(1) 触发迁移
- 场景:节点扩容、缩容、负载不均衡或节点故障。
- 决策:协调者(如控制节点)决定将分区
P从节点A迁移到节点B,并更新元数据版本。
(2) 数据复制
- 增量同步:
- 节点
A开始将分区P的 全量数据 发送给节点B。 - 同时,节点
A记录迁移期间对分区P的 增量写入操作(如写日志 WAL)。
- 节点
- 最终同步:
- 全量数据传输完成后,节点
A将增量写入日志发送给节点B,确保数据一致。 - 节点
B应用所有操作后,数据与节点A完全同步。
- 全量数据传输完成后,节点
(3) 客户端路由切换
- 元数据广播:协调者将新版本的元数据(分区
P归属节点B)广播给所有客户端和节点。 - 双写过渡(可选):
- 客户端在一段时间内同时向节点
A和B写入,确保切换期间数据不丢失。 - 节点
B接收写入后,同步回节点A(反向同步),避免数据冲突。
- 客户端在一段时间内同时向节点
(4) 旧节点清理
- 迁移完成后,节点
A删除分区P的数据,释放资源。
3. 关键设计
(1) 迁移期间读写处理
- 读操作:
- 客户端根据元数据版本决定从节点
A或B读取(可能短暂读到旧数据)。 - 部分系统允许从新旧节点同时读取,合并结果(需处理一致性)。
- 客户端根据元数据版本决定从节点
- 写操作:
- 写入仍发往旧节点
A,同时同步到新节点B(通过增量日志)。 - 元数据切换后,写入直接发往新节点
B。
- 写入仍发往旧节点
(2) 一致性保证
- 原子性切换:元数据版本变更需原子性操作,避免客户端读取到中间状态。
- 最终一致性:迁移期间允许短暂不一致,但最终所有节点数据一致。
(3) 容错机制
- 迁移失败回滚:若节点
B同步失败,协调者回滚元数据版本,客户端继续使用节点A。 - 重试机制:数据传输中断后自动重试,避免人工干预。
4. 实例:Apache Kafka 分区迁移
以 Kafka 为例,其分区迁移流程如下:
- 触发迁移:管理员通过
kafka-reassign-partitions工具触发迁移。 - 数据复制:源 Broker 将分区数据复制到目标 Broker,同时持续接收新消息。
- 切换 ISR(In-Sync Replicas):目标 Broker 加入 ISR 列表,成为正式副本。
- 客户端更新元数据:客户端通过 Metadata 请求感知新副本位置。
- 旧副本下线:源 Broker 移除副本,完成迁移。
总结
固定数量分区的实时迁移通过 元数据版本控制 + 增量数据同步 + 客户端路由切换 实现,核心目标是:
- 无服务中断:迁移期间持续服务。
- 数据一致性:最终所有副本数据一致。
- 自动化:减少人工干预,适应动态集群变化。 这种设计牺牲了部分迁移期间的性能(如双写开销),但保证了系统的可用性和可扩展性。
4.3. 动态分区 (Dynamic Partitioning)
- 概念:
- 分区数量 不固定。
- 当分区数据量 超过阈值 时,自动 分裂 (Split) 成两个大致相等的分区。
- 当分区数据量 低于阈值 时,可以与相邻分区 合并 (Merge)。 (类似 B 树)
- 优点:
- 分区数量 自动适应 数据总量。
- 分区大小保持在 合理范围 内。
- 缺点:
- 冷启动问题: 空数据库只有一个分区,初始写入负载集中,直到分裂发生。可通过 预分割 (Pre-splitting) 缓解 (需要预知键分布)。
- 适用性: 常用于 键范围分区,但也适用于 散列分区。
- 实例: HBase, RethinkDB, MongoDB (≥ 2.4)。
4.4. 按节点比例分区 (Partitioning Proportionally to Nodes)
- 概念:
- 每个节点 负责 固定数量 的分区。
- 总分区数与 节点数量成正比。
- 再平衡 (添加节点): 新节点 随机选择 集群中若干个现有分区,将它们 分裂,新节点负责其中一半,原节点保留另一半。
- 优点:
- 随着节点增减,每个分区的大小能 保持相对稳定。
- 缺点:
- 随机分裂可能导致 短暂不均 (分区数多时可缓解)。
- 通常需要 散列分区 来支持随机边界选择。
- 实例: Cassandra (vnode 机制), Ketama (Memcached 库)。
4.5. 运维:手动还是自动再平衡 (Manual vs. Automatic Rebalancing)
- 全自动:
- 优点: 运维简单。
- 缺点: 可能 不可预测,再平衡本身是重操作,可能在系统已过载时触发,加剧问题甚至导致 级联故障。
- 全手动:
- 优点: 完全可控,更安全。
- 缺点: 运维负担重。
- 半自动 (混合模式): 系统建议分区迁移方案,管理员确认 后执行。
- 优点: 结合了自动化便利性和人工控制的安全性。
- 实例: Couchbase, Riak, Voldemort。
5. 请求路由 (Request Routing / Service Discovery)
问题: 客户端如何知道应该将请求 (读/写键 “foo”) 发送到哪个节点的哪个分区?尤其在再平衡导致分区-节点映射变化时。
方案 (如图 6-7):
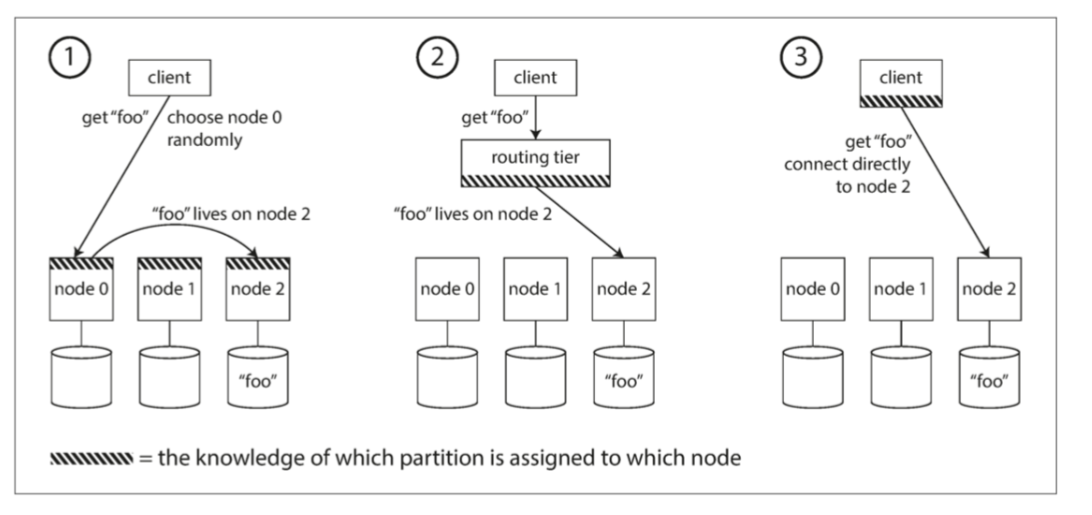 **图 6-7 将请求路由到正确节点的三种不同方式
**图 6-7 将请求路由到正确节点的三种不同方式
任意节点 + 转发:
- 客户端连接 集群中的任意一个节点 (如通过轮询负载均衡器)。
- 如果该节点负责请求的分区,则直接处理。
- 否则,该节点 查询正确节点 并将请求 转发 过去,接收响应再返回给客户端。
- 内部通信: 节点间通常使用 Gossip 协议 传播集群状态和分区映射信息。
- 优点: 无需外部协调服务。
- 缺点: 节点需要承担路由/转发逻辑。
- 实例: Cassandra, Riak。
路由层 (Routing Tier):
- 客户端 始终连接 一个 独立的路由服务 (或一组路由服务)。
- 路由层 维护 最新的分区-节点映射。
- 它 解析请求,确定目标节点,并将请求 转发。
- 路由层本身 不处理数据读写,只负责路由和负载均衡。
- 优点: 节点逻辑简单,客户端逻辑简单。
- 缺点: 路由层成为潜在瓶颈或单点故障 (需高可用)。
- 实例: MongoDB (mongos 进程), Espresso (使用 Helix), Couchbase (Moxi)。
客户端感知分区 (Client-Side Partitioning):
- 客户端 直接从协调服务或节点获取 分区-节点映射信息。
- 客户端 直接连接 到持有目标分区的 正确节点。
- 优点: 减少网络跳数,可能降低延迟。
- 缺点: 客户端实现更复杂,需要处理映射更新逻辑。
路由信息维护 (关键问题: 如何保持映射最新且一致):
协调服务 (Coordination Service):
- 使用 ZooKeeper, etcd, Consul 等。
- 节点在协调服务中 注册 自己以及负责的分区信息。
- 路由层或客户端 订阅 协调服务中的信息变更通知。
- 当分区分配变化或节点增删时,协调服务 通知 订阅者更新路由表。
- 实例: HBase, SolrCloud, Kafka, Espresso/Helix (依赖 ZK), MongoDB (自有 Config Server)。(如图 6-8)
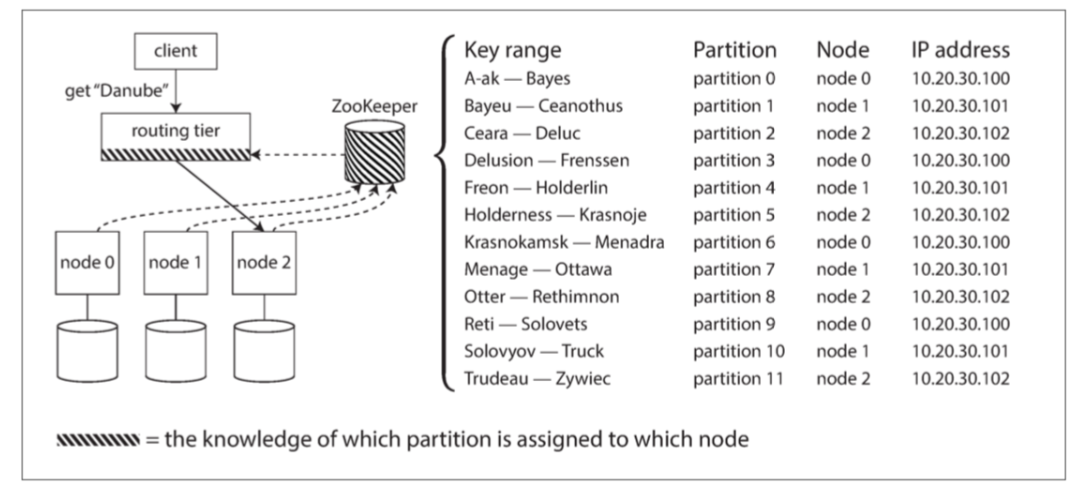 图 6-8 使用 ZooKeeper 跟踪分区分配给节点。
图 6-8 使用 ZooKeeper 跟踪分区分配给节点。
Gossip 协议: 节点间 点对点 传播集群状态变化。 (如 Cassandra, Riak)。
寻找入口点: 客户端如何找到路由层或第一个连接的节点?通常使用 DNS 解析服务名到一个或多个 IP 地址。节点/路由层地址变化相对不频繁。
6. 执行并行查询 (Parallel Query Execution)
- 主要针对 分析型查询 (OLAP) 和 大规模并行处理 (MPP) 数据库。
- 复杂查询 (含 Join, Filter, Group By, Aggregation) 被 查询优化器 分解为多个阶段和子任务。
- 这些子任务可以在 不同节点的分区上并行执行。
- 极大提升了扫描大型数据集的查询性能。
- 更详细内容见 第十章。
本章小结
- 分区是为了 可伸缩性,将大数据集和高负载分散到多台机器。
- 核心目标是 均匀分布 数据和负载,避免 热点。
- 主要分区策略:
- 键范围分区: 利于范围查询,但有热点风险。动态分裂/合并。
- 散列分区: 负载均衡更好,但范围查询低效。固定分区数+移动 或 动态分区 或 按节点比例分区。
- 次级索引分区策略:
- 文档分区 (本地索引): 写简单,读需 Scatter/Gather。
- 关键词分区 (全局索引): 读高效,写复杂 (可能异步)。
- 再平衡 是分区数据库运维的关键,需在可用性、效率和安全间权衡 (自动 vs. 手动)。
- 请求路由 确保客户端能找到正确的分区,常用协调服务或 Gossip 协议维护路由信息。
- 分区设计使得大部分操作可以在单分区内独立进行,但也引入了 跨分区操作 的复杂性 (将在后续章节讨论,如事务)。