
MySQL 的数据目录
核心概念:
MySQL 数据库的数据、元数据、日志等信息都存储在数据目录中。理解数据目录的结构和内容,对于数据库管理、备份恢复、故障排查至关重要。
1. 数据目录的重要性
- 原理: MySQL 实例启动时,会读取数据目录来初始化。数据目录是数据库的“家”,所有数据都“居住”于此。
- 应用:
- 备份与恢复: 全量备份通常就是备份整个数据目录。理解目录结构有助于快速恢复。
- 迁移: 数据库迁移通常涉及数据目录的拷贝。
- 故障排查: 错误日志、慢查询日志等位于数据目录,是排查问题的关键。
- 空间管理: 监控数据目录空间,防止磁盘爆满导致数据库崩溃。
2. 确定数据目录
通过查询
datadir系统变量确定路径:SHOW VARIABLES LIKE 'datadir';
3. 数据目录结构
- 数据库: 每个数据库对应数据目录下的一个子目录。
db.opt文件(MySQL 8.0 前): 存储数据库的默认字符集和排序规则。(8.0 后已废弃,元数据统一存储在数据字典中)
- 表:
.frm文件(MySQL 8.0 前): 存储表的元数据(列定义、数据类型、索引等)。(8.0 后已废弃,元数据统一存储在数据字典中)- 跨存储引擎(InnoDB、MyISAM 等都有)。
- 损坏可能导致表无法打开。
- 表数据存储(取决于存储引擎):
- InnoDB:
- 表空间: 数据和索引存储在表空间中。
- 系统表空间 (ibdata1): 早期默认所有表共享。
- 独立表空间 (.ibd): MySQL 5.6.6 后默认每个表独立。
innodb_file_per_table参数控制(建议开启)。- 易于空间回收(
ALTER TABLE ... ENGINE=InnoDB;)。 - 可单独迁移表(拷贝
.ibd)。
- MyISAM:
.MYD文件:存储数据。.MYI文件:存储索引。- 不支持事务,易损坏(需定期用
myisamchk检查修复)。
- InnoDB:
- 视图:
.frm文件(MySQL 8.0 前):存储视图定义(虚拟表,不存储实际数据)。
- 其他文件:
- 服务器进程文件:存储进程 ID。
- 服务器日志文件:查询日志、错误日志、二进制日志等。
- SSL 和 RSA 证书和密钥文件:用于安全通信。
4. 文件系统对数据库的影响
- 原理: 数据库构建于文件系统之上,文件系统特性直接影响数据库性能和行为。
- 应用:
- 文件系统选择: 选择适合数据库负载的文件系统(如 XFS、ext4)。
- 参数调优: 调整文件系统参数(如
atime、noatime)优化 I/O。 - 磁盘 I/O 调度器: 选择合适的调度器(deadline、noop、cfq)提高吞吐。
- 命名限制: 数据库和表名受文件系统最大长度限制。
- 特殊字符处理: 特殊字符会被映射为
@+编码值。 - 文件大小限制: 表数据文件大小受文件系统最大文件大小限制。
5. MySQL 系统数据库
mysql: 存储用户账户、权限、存储过程、事件、日志等。information_schema: 保存所有数据库的元数据(表、视图、触发器、列、索引等)。应用: 查询元数据信息:
-- 查询所有表的名称和创建时间 SELECT table_name, create_time FROM information_schema.tables WHERE table_schema = 'your_database_name'; -- 查询某个表的列信息 SELECT column_name, data_type, column_type FROM information_schema.columns WHERE table_schema = 'your_database_name' AND table_name = 'your_table_name';
performance_schema: 记录性能状态信息(执行的语句、内存使用等)。应用: 分析性能瓶颈:
-- 查询执行时间最长的 SQL 语句 SELECT * FROM performance_schema.events_statements_summary_by_digest ORDER BY sum_timer_wait DESC LIMIT 10; -- 查询某个表的 I/O 统计信息 SELECT * FROM performance_schema.file_summary_by_instance WHERE file_name LIKE '%/your_database_name/your_table_name.ibd';
sys: 通过视图结合information_schema和performance_schema,方便查看性能信息。- 例如:
sys.schema_table_statistics查看表统计信息,sys.x$memory_by_thread_by_current_bytes查看线程内存。
- 例如:
InnoDB 的表空间
核心概念:
InnoDB 以表空间为抽象层管理数据存储。表空间由多个页(Page) 组成,并引入区(Extent) 和段(Segment) 的概念来优化管理。
1. 表空间存在的意义(根本原因)
- 抽象: 将 InnoDB 与底层文件系统隔离。
- 好处:
- 可移植性: 更易移植到不同操作系统和文件系统。
- 灵活性: 支持不同页大小、存储格式等。
- 性能优化: 针对数据库特点优化(预分配、批量写入等)。
2. 页(Page)的重要性
- 原理: InnoDB I/O 操作的基本单位(默认 16KB)。
- 补充:
innodb_page_size参数可配置页大小(通常不修改)。- 页结构:页头(Page Header)存储类型、校验和、LSN 等;剩余部分存储数据。
- LSN (Log Sequence Number): 页中记录的 LSN 用于崩溃恢复,确保数据一致性。
- 页分裂:数据满后插入新数据导致,影响性能,应避免。
3. 表空间类型
- 系统表空间: 整个 MySQL 进程只有一个(ID 为 0),存储系统属性和数据字典。
- 结构复杂,包含多个特殊页类型和链表。
- 包含双写缓冲区(Doublewrite Buffer):防止部分写入问题。
- 原理: 数据页先写入双写缓冲区,再写入数据文件,崩溃时可恢复。
- 包含 Insert Buffer:缓存非聚集索引插入,减少随机 I/O。
- 原理: 将多次插入合并为一次批量写入。
- 独立表空间: 每个表一个(
.ibd文件),存储表数据和索引。- 结构相对简单。
4. 区(Extent)和段(Segment)的设计
- 为什么要有区?
- 减少碎片: 一组连续的页(64 个,1MB),减少外部碎片。每256个区为一组
- 提高 I/O 效率: 一次读取整个区,减少磁盘寻道。
- 为什么要有段?
- 组织数据: 按逻辑关系组织(索引叶子节点和非叶子节点分段存储)。
- 空间管理: 方便空间分配回收(可整体释放段)。
- 应用:
- 碎片整理:
OPTIMIZE TABLE整理碎片,回收空间。 - 监控: 通过
information_schema.INNODB_SYS_TABLESPACES和information_schema.INNODB_SYS_DATAFILES查看信息。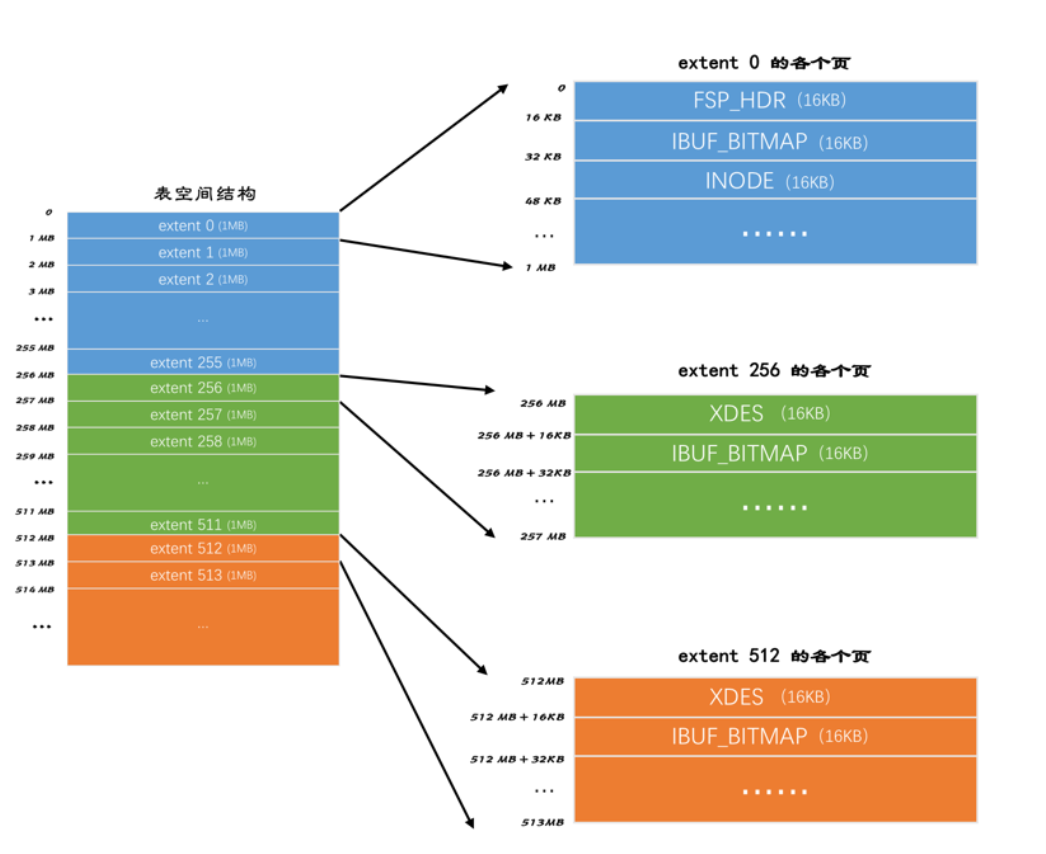 第一个组(extent 0 ~ extent 255):
第一个组(extent 0 ~ extent 255):
- 碎片整理:
FSP_HDR类型:这个类型的页用于登记整个表空间的一些整体属性以及本组所有区的属性。整个表空间只有一个FSP_HDR类型的页。
IBUF_BITMAP类型:这个类型的页存储本组所有区的所有页关于INSERT BUFFER的信息。
INODE类型:这个类型的页存储了许多称为INODE的数据结构,用于管理段(segment)。
其他组(extent 256、extent 512等):
XDES类型:全称是extent descriptor,用于登记本组256个区的属性。例如,extent 256区中的XDES类型页存储extent 256 ~ extent 511这些区的属性,extent 512区中的XDES类型页存储extent 512 ~ extent 767这些区的属性。
IBUF_BITMAP类型:与第一个组中的IBUF_BITMAP类型页类似,存储本组所有区的所有页关于INSERT BUFFER的信息。
总结
表空间被划分为许多连续的区,每个区默认由64个页组成,每256个区划分为一组。每个组的最开始的几个页类型是固定的,这些页类型包括FSP_HDR、IBUF_BITMAP、INODE(第一个组)和XDES、IBUF_BITMAP(其他组)。这些固定的页类型用于存储表空间的属性、区的属性以及段的管理信息,从而实现对表空间的有效管理。
5. 区的分类和管理
- 区状态:
FREE:空闲。FREE_FRAG:有剩余空间的碎片区。FULL_FRAG:无剩余空间的碎片区。FSEG:附属于某个段。
- XDES Entry: 每个区对应一个XDES Entry结构,记录区的属性,通过链表连接(
FREE、FREE_FRAG、FULL_FRAG),方便管理。
6. 段的结构和管理
- INODE Entry: 每个段对应一个
INODE Entry结构,记录属性,包括对应的段内零散页的地址以及附属于该段的FREE、NOT_FULL、FULL链表的基节点。INODE Entry结构存在于类型为INODE的页中。 - 链表管理: 段中区通过链表管理(
FREE、NOT_FULL、FULL),快速找到可用区。- 链表作用:
FREE链表:快速找到完全空闲的区。NOT_FULL链表:快速找到段内未满的区。FULL链表:记录已满的区,避免再次分配。
- 为什么需要
FREE_FRAG和FULL_FRAG?- 已分配给段的区不应从
FREE链表摘除。 FULL_FRAG区已满,不应再分配。FREE_FRAG区还有空间,但不能给其他段。 在InnoDB存储引擎中,段(segment)的形成依据主要包括以下两个方面:
- 已分配给段的区不应从
- 链表作用:
数据存储需求
表或索引的大小:当表或索引的数据量较小时,可能只需要零散的页来存储数据。随着数据量的增加,需要更多的存储空间,这时就会将多个区或零散页组合成一个段,以满足数据存储的需求。
存储结构:每个表的聚簇索引和二级索引都需要对应的段来存储数据。聚簇索引的叶子节点和非叶子节点通常分别对应不同的段,以优化数据访问和存储。
空间分配策略
连续分配:为了提高数据访问的效率,InnoDB倾向于将连续的区分配给一个段。这样可以减少随机I/O操作,提高顺序I/O的效率。
零散分配:在某些情况下,当无法找到连续的区时,InnoDB会使用零散的页来存储数据。这些零散页也会被组合成一个段,以便进行统一的管理和分配。
综上所述,段是基于数据存储需求和空间分配策略形成的逻辑存储单元,它由多个区或零散页组成,用于高效地管理数据的存储。
7. InnoDB 数据字典
- 原理: 存储数据库元数据(表、列、索引、表空间等)。MySQL 8.0 后全部存储在系统表空间。
- 补充:
- 数据字典表: 一系列内部系统表(
SYS_TABLES、SYS_COLUMNS等),不能直接访问,通过information_schema视图查看。 - 数据字典缓存: InnoDB 缓存数据字典信息,提高访问速度。
- 数据字典表: 一系列内部系统表(
补充说明:
- 崩溃恢复: InnoDB 使用 redo log 和 undo log 进行崩溃恢复。redo log 记录了数据页的修改,undo log 记录了事务开始前的旧版本数据。
- 事务隔离: InnoDB 通过 MVCC (多版本并发控制) 实现事务隔离,每个事务看到的数据版本可能不同。